
AI Model
Complete Guide to AI Image Generation Using DALL·E 3

- Share
- Tweet /data/web/virtuals/375883/virtual/www/domains/spaisee.com/wp-content/plugins/mvp-social-buttons/mvp-social-buttons.php on line 63
https://spaisee.com/wp-content/uploads/2025/07/dragon2-1-1000x600.png&description=Complete Guide to AI Image Generation Using DALL·E 3', 'pinterestShare', 'width=750,height=350'); return false;" title="Pin This Post">
If you already know the basics of prompting, come join us to level up your skills with DALL·E 3.
In this tutorial, you’ll learn advanced techniques and creative tricks to generate stunning images with precision and style.
Section 0: Getting Started — Logging In and Accessing DALL·E
What is DALL·E 3?
DALL·E 3 is the latest image generation model by OpenAI, integrated directly into ChatGPT. It allows users to generate and edit images using natural language prompts.
Where to access it:
The most up-to-date version of DALL·E is available inside ChatGPT (https://chat.openai.com) for users with a ChatGPT Plus subscription.
Steps to log in and start generating images:
- Go to https://chat.openai.com
- Sign up or log in to your OpenAI account.
- Click your name or profile icon in the bottom left and go to Settings.
- Under “My Plan”, upgrade to ChatGPT Plus ($20/month).
- In the model switcher at the top, select GPT-4 (you’ll be using GPT-4o, which includes DALL·E 3).
- You’re now ready to generate images by typing prompts into the chat.
To generate an image, simply enter a prompt like this:
“Create an image of a castle floating in the clouds, digital painting style.”
ChatGPT will return the generated image directly in the conversation.

Section 1: The Fundamentals — How DALL·E Thinks
DALL·E is a language-to-image model. It doesn’t “see” or “imagine” like a human. It creates images by predicting visual outcomes based on text descriptions. That means it responds best to clear, descriptive language—especially language grounded in visual, artistic, and emotional cues.
To get great results, you must describe your scene as though explaining it to a professional illustrator or cinematographer.
Section 2: Structuring a Strong Image Prompt
To reliably control the results, write prompts that include specific visual attributes. The more you define the visual world, the less randomness DALL·E introduces.
Use this structure for your prompts:
[Subject] doing [Action], in [Setting/Environment], at [Time of Day], with [Lighting and Color], in the style of [Artist or Medium], conveying a [Mood or Emotion]
Example:
“A woman standing in a wheat field at sunset, with warm golden light, soft shadows, and a calm expression, in the style of an oil painting, evoking peace and nostalgia.”

Section 3: Visual Thinking — Moving from Concept to Prompt
Before writing, ask:
- What is the subject?
- What is the setting or environment?
- What emotion or atmosphere do I want to create?
- What style or medium should it look like?
- What kind of lighting and color palette would match?
Example Concept
Idea: “A sense of isolation in a futuristic world”
Step-by-step translation:
- Subject: A lone figure
- Environment: Dystopian cityscape
- Mood: Isolation
- Style: Sci-fi concept art
- Time and light: Night, glowing neon
Prompt:
“A lone figure walking down an empty neon-lit street in a futuristic city, deep shadows and glowing signs, night scene, cinematic sci-fi style, inspired by Blade Runner.”
This prompt tells DALL·E what to show, how it should feel, and what style to emulate.
Section 4: Controlling Style
DALL·E supports a wide range of styles. Naming a style in your prompt helps guide the composition, color, and texture of the image.
Common style terms you can use:
- Oil painting
- Watercolor
- Ink drawing
- Digital illustration
- 3D render
- Pixel art
- Retro comic book
- Cyberpunk
- Ukiyo-e (Japanese woodblock)
- Surrealism
- Art deco
- Minimalist line art
Example prompt:
“A giraffe wearing sunglasses walking through Times Square, in the style of a 1990s comic book cover.”

Why it works:
You’ve described the scene and given a visual reference style, which DALL·E can map to a specific type of color, texture, and composition.
Section 5: Iterating and Refining Prompts
Creating high-quality images with DALL·E is an iterative process. Your first image is a sketch. Each following prompts should refine or evolve it.
Start simple:
“A dragon flying over mountains.”
Add detail:
“A golden dragon flying above snow-covered mountains under a twilight sky, glowing clouds, fantasy illustration.”
Refine style and mood:
“A golden dragon soaring above icy mountains at dusk, wings reflecting orange light, cinematic fantasy art in the style of Magic: The Gathering card illustrations.”
Each refinement clarifies:
- Subject appearance
- Lighting
- Emotion
- Visual format
Section 6: Using Inpainting to Edit Images
DALL·E 3 (via ChatGPT Plus) supports inpainting, which allows you to change part of an image after it has been generated.
How to use inpainting:
- Generate an image with a prompt.
- Hover over the image in ChatGPT and click the “Edit” (pencil) icon.
- Use the brush to select the area you want to modify.
- Enter an instruction, such as “Replace the tree with a small pagoda.”
- DALL·E will regenerate just the selected area.
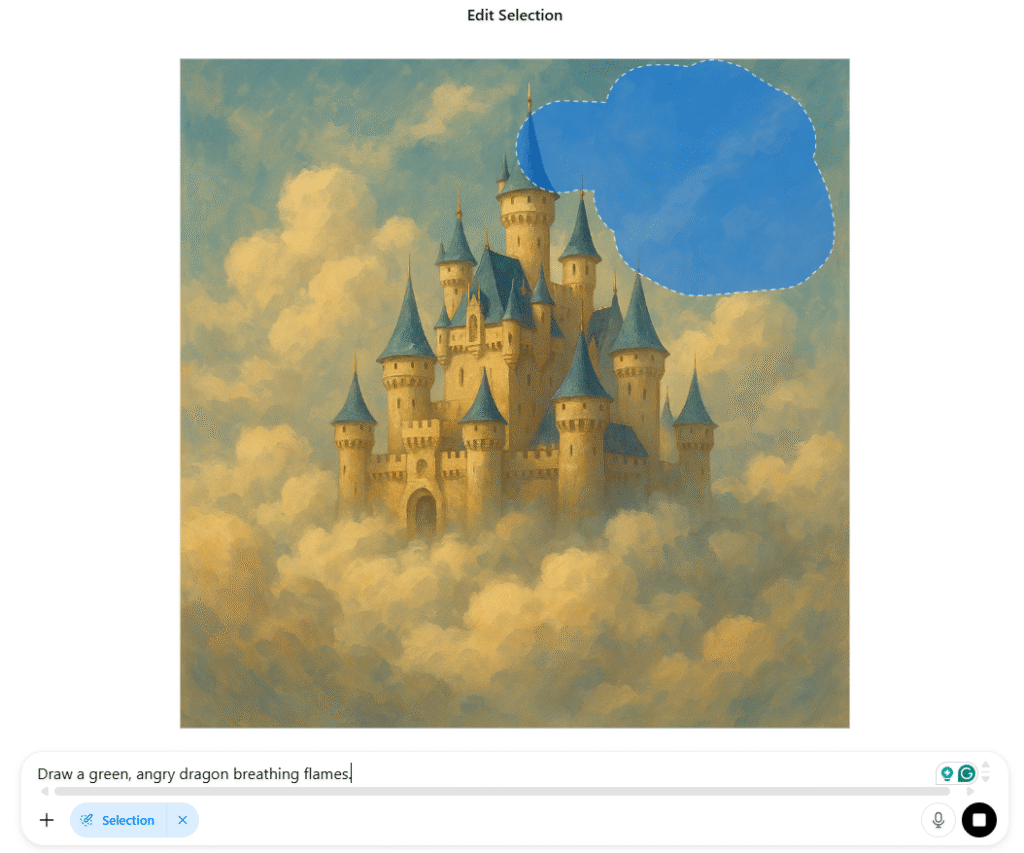
This is ideal for:
- Adding or removing elements
- Correcting details (lighting, faces, objects)
- Evolving a scene step-by-step
Section 7: Creating Custom Visual Styles
You can direct DALL·E to create unique visual styles by blending influences.
Example prompt:
“A cityscape rendered in a hybrid style combining Japanese ukiyo-e woodblock art and modern architectural sketching, monochrome with red accents.”

This kind of prompt works because it:
- Names two style references
- Specifies the medium and texture (woodblock + sketch)
- Introduces a color limitation (monochrome + red)
You can blend:
- Historical art styles with sci-fi
- Real-world cultural references with digital formats
- Natural textures with abstract design
Section 8: Composition and Directional Language
To further control the image, include composition cues. DALL·E understands basic photographic and cinematic language.
Terms to use:
- Wide shot / close-up
- Bird’s-eye view / top-down / isometric
- Symmetrical / centered / off-center
- Portrait orientation / landscape orientation
- Backlighting / front lighting / rim light / ambient light
- Mood words: eerie, joyful, tranquil, apocalyptic
Example prompt with composition:
“A child looking out a window at a rainy cityscape, viewed from behind, soft diffused lighting, shallow depth of field, photographic realism.”
Here, you’re directing the perspective, lighting, and style.
Section 9: Prompt Templates for Common Use Cases
Character Portrait
“A [type of person or creature], wearing [style or clothing], in [pose or expression], background of [environment], in the style of [artist or medium], with [lighting and mood].”
Example:
“A medieval knight in weathered armor, standing in profile against a stormy battlefield, realistic digital painting with dramatic lighting.”
Landscape
“A [landscape or environment], under [time of day and weather], seen from [angle], in the style of [painting or media], conveying a sense of [emotion or scale].”
Example:
“A vast desert at sunset, viewed from a high dune, shadows stretching far, soft orange and purple tones, in the style of a watercolor painting, evoking loneliness.”
Surreal Concept
“A [subject or object] in a world where [unusual twist], rendered in [style or medium], with [color palette and lighting], inspired by [surrealist artist or film].”
Example:
“An elephant made of clock gears walking across a frozen ocean, in the style of Salvador Dalí, with melting shadows and surreal lighting.”

Section 10: Ethical Use and Exporting Images
Saving and using images:
- Right-click on generated images to save.
- You are permitted to use DALL·E images for personal and commercial use under OpenAI’s terms.
- Avoid using generated images to impersonate real individuals or mislead others about authorship.
Things to avoid:
- Generating nudity, gore, or harmful content
- Trying to recreate real people’s likenesses
- Misusing AI art in misleading advertising or journalistic contexts
Section 11: Practice Challenge – Evolve a Prompt in 3 Steps
Starting prompt:
“A lighthouse on a cliff”
Refinement 1:
“A white lighthouse on a jagged cliff at sunset, waves crashing below, digital painting.”
Refinement 2:
“A towering white lighthouse on a crumbling cliff during a storm, lightning striking in the background, dramatic shadows, painted in 19th-century Romantic style.”
Refinement 3:
“A surreal scene of a lighthouse floating above the ocean, beams of light piercing the sky, oil on canvas style with bold brushstrokes, dreamlike atmosphere.”

This practice teaches:
- Prompt layering
- Mood shaping
- Style transitions
- Creative remixing
Summary
AI image generation is a creative process that rewards visual thinking, iteration, and control. To become proficient with DALL·E, you need to:
- Write descriptive, structured prompts
- Direct style, lighting, and composition
- Iterate and refine results step-by-step
- Use inpainting to edit specific areas
- Explore and invent custom styles
- Think like a visual storyteller













In the last two years, generative AI has shifted from human‑assisted chatbots to autonomous agents — systems that can plan, reason, use tools, learn from past tasks, and carry out multi‑step workflows across software environments. These agents do more than answer questions: they act on behalf of users, pursuing goals with autonomy and continuity of context.
Among the many contenders today, three rule the conversation: OpenAI’s ChatGPT (with GPT‑5.1 / GPT‑5.2 agent capabilities), Anthropic’s Claude (particularly the latest Opus 4.5 line), and Google’s Gemini (up through Gemini 3 Pro / Deep Think). These form the de facto “big three” of commercial, high‑performance AI agents as of early 2026. Below, I’ll examine what they can do, how they fail, and which one leads in different real‑world domains.
What It Means to Be an AI Agent in 2026
Let’s define terms before comparing capabilities: an AI agent isn’t just a chatbot. It’s a system that can pursue a long‑running goal on your behalf, use tools like web search and APIs, retain memory across tasks, plan multi‑step actions, and adjust strategies based on outcomes — sometimes even retrying or optimizing solutions if the initial attempt fails. It’s the difference between answering “book me a hotel in Prague” and actually carrying out the reservation across the booking website, handling errors, and confirming with actionable output.
In research literature, agents are expected to reason about tasks, plan, maintain a persistent memory/state, and show an ability to adapt or recover from mistakes. Current commercial agents approximate these qualities with varying degrees of autonomy, reliability, and safety.
I. ChatGPT (OpenAI GPT‑5.1 / 5.2)
OpenAI’s flagship continues to be the most widely deployed and deeply integrated agentic system in the world. Its capabilities extend far beyond static chat.
Capabilities:
At its core, ChatGPT has strong reasoning, large context handling, and flexible integration with tools (browsing, plugins, code execution, file handling). For autonomous actions — especially in the ChatGPT Plugins / Tools ecosystem — it can:
• Plan and manage multi‑step tasks such as travel arrangements, scheduling, and research workflows.
• Access the web (when browsing is enabled) and combine search results with reasoning.
• Use third‑party tools via plugins (booking systems, calendars, spreadsheets, emails, etc.) to operationalize real tasks.
• Understand and work with large context windows (hundreds of thousands of tokens), making it strong for deep research and long projects.
In tests, ChatGPT excels in deep research tasks — synthesizing complex, cross‑referenced information — and in collaborative content generation across domains like technical documentation, scenario planning, or creative writing. Users report that its conversational style makes complex tasks feel intuitive and accessible.
Where It Falls Short:
Despite its widespread adoption, ChatGPT’s autonomy has limitations:
• Partial agent autonomy: It often suggests next steps instead of executing them reliably. For example, booking a hotel might require user confirmation at multiple stages. Some plugin ecosystems still depend on explicit user input. This makes it semi‑agentic, rather than fully hands‑off.
• Browsing reliability: Web searches can be outdated or misinterpreted unless carefully guided by prompt instructions. Additionally, its browsing is reactive, not proactive. It does not continuously watch and update tasks as external changes occur.
• Social and safety restrictions: Hallucinations still occur under stress (complex sequences of actions across multiple tools), and guardrails can limit responses about certain topics.
In benchmarks for reasoning and context, GPT‑5.1 shows strong performance with low latency and high reasoning scores compared to previous generations, but it’s not always the first choice for specialized tasks like competitive programming or safety‑critical decisioning.
Typical Use Cases Seen in the Wild:
Users across social platforms and developer communities commonly deploy ChatGPT for:
• Complex research Aggregation: Academic summaries, legal and medical explanations, business intelligence.
• Team workflows: Automated meeting notes, email drafts, technical specs, structured output like tables or JSON.
• Integrated workflows: ChatGPT Plugins for travel, scheduling, and CRM tasks — albeit with intermediary confirmations.
Sentiment from users is generally high: they praise its conversational reasoning and trust its summaries, but many note that full task automation often still requires human oversight. Discussions highlight that ChatGPT is best where the precision of understanding and nuance matter most.
II. Claude (Anthropic — especially Opus 4.5 and Cowork)
Claude’s reputation has sharpened into a productivity and safe‑operation champion. Unlike systems optimized for novelty or entertainment, Claude has been engineered with explicit emphasis on safety, structured outputs, and multi‑step task planning.
Capabilities:
Anthropic’s latest Claude variants — especially Opus 4.5 — demonstrate several real advances:
• Dominant performance in structured tasks like coding, logical planning, and enterprise workflows. It topped rigorous coding benchmarks ahead of other major models.
• Claude Cowork, a new desktop and browser automation agent, makes tangible progress in functional autonomy. It can organize files, convert document types, generate reports, and even clean email inboxes without constant user prompting, handling tools like folders, browsers, and permissions.
• Multi‑step task reasoning is robust: Claude sequences tasks correctly and rarely “forgets” mid‑workflow. Users report it being particularly good at tasks demanding pragmatics: planning, going back to revise previous steps, and adjusting outcomes.
• Safety and alignment: Claude models are considered safe and less prone to hallucinations in sensitive contexts. They also incorporate reasoning constraints that help keep outputs grounded.
Where Claude Stumbles:
• Multimodal limitations: Although Claude can consume long contexts and structured data well, it does not yet match competitors in video or native multimodal content generation.
• Less integrated in web search ecosystems: Unlike Gemini or ChatGPT’s browsing ecosystem, Claude’s autonomous web interaction is more restricted — meaning less timely access to real‑time information unless integrated with custom tool chains.
• Cowork is still in beta: Users note occasional bugs; security concerns also arise because autonomous tool execution can expose sensitive file interactions if permissions are misconfigured.
Real Usage Patterns:
Across Reddit, professional blogs, and developer forums, Claude is being used for:
• Coding automation: Developers using Opus 4.5 praise concise reasoning for complex refactors.
• Formal writing and content generation: From academic pieces to business briefs, Claude’s outputs are considered clean, coherent, and easier to structure into publishable form.
• Workflow automation: Using Cowork, users automate parts of their desktop workflows — especially repetitive manual steps like mail processing or file sorting.
People tend to be satisfied with Claude where precision and reliability matter. Some user sentiment emphasizes that Claude feels more like an assistant colleague than a generic chatbot — a choice many consultants and writers prefer.
III. Google Gemini (especially Gemini 3 Pro and Deep Think)
Gemini has recently surged up the capability ladder. Google has positioned it as a generalist with multimodal strengths and deep integration with search, image/video understanding, and tools.
Capabilities:
Gemini’s strengths lie in three domains:
• Multimodal intelligence: It can process and act on images, video, and audio natively, offering deeper interpretations than most competitors. This is hugely beneficial for workflows where visual context matters.
• Large context windows: Gemini 3 Pro supports enormous context — in some tests pushing millions of tokens via compression techniques — enabling it to digest books, entire codebases, or extensive document collections at once.
• Reasoning leadership: In benchmarks, Gemini 3 Pro scored at the top, often outperforming rivals in complex problem solving and general knowledge tasks.
• Integration with search: Unlike static model responses, Gemini’s live search connections mean agents can fetch up‑to‑date knowledge instead of relying on a fixed training cutoff.
Where It Fails:
• Task autonomy still developing: While Gemini excels in understanding and reasoning, its agentic execution — especially in real world workflows like bookings or multi‑system interactions — is not yet as polished as Claude Cowork’s emerging automation or ChatGPT’s plugin ecosystem.
• Guardrails and corporate constraints: Because of safety guardrails, certain content categories (like political topics) are restricted. Users on social forums note that while factual accuracy is high, “edgier” or nuance‑heavy conversations get softer responses.
• Latency and integration gaps: For very long tasks that require orchestrating multiple external tools, Gemini sometimes lags or expects user prompts rather than silently chaining actions.
What Users Are Using Gemini For:
• Knowledge work with multimodal inputs: Designers, researchers, and analysts use Gemini for tasks where visual context and deep understanding converge.
• Factual reasoning tasks: In social forums and developer circles, Gemini is praised for accuracy and breadth of knowledge.
• Creative outputs involving images and video: Users who want narrative content + visual elements often choose Gemini for integrated outputs.
Overall sentiment sees Gemini as a research and multimodal powerhouse — not yet the most autonomous agent in terms of cross‑tool task execution, but unmatched for complex interpretation.
Common Real‑World Use Cases People Actually Try (and Talk About)
From industry blogs, AI communities, and Reddit threads, we see strong patterns of how people are actually using AI agents across domains:
• In business workflows, agents monitor brand mentions, reply on social media, automate scheduling, categorize expenses, and suggest optimizations rather than just respond to isolated queries.
• Sales teams rely on agents to qualify leads, answer preliminary questions, schedule demos, and generate pre‑sales materials.
• Customer support functions are prototyping round‑the‑clock support agents that identify issues and escalate complex queries to humans when needed.
• Developers use agents specifically for code generation, testing, refactoring, and terminal‑level automation — often including live debugging workflows.
• In personal productivity, agents assist with inbox triage, document conversion, travel planning, and meeting preparation — with varying degrees of success depending on the platform.
In general, users are happiest when agents augment structured tasks (like coding, writing drafts, research synthesis) and least satisfied when agents attempt end‑to‑end autonomous workflows (like fully automated booking or financial transactions), where brittle integrations and safety guardrails frequently cause friction.
Limitations and Failures Across All Agents
Despite rapid advances, today’s agents share persistent weaknesses.
Hallucination and confidence miscalibration remains common. Even the top models sometimes fabricate plausible‑sounding but incorrect information, especially under ambiguous or adversarial prompts.
Task brittleness is a recurring theme — agents often stumble on sequences involving multi‑system or multi‑application workflows unless carefully scaffolded with explicit steps.
Security vulnerabilities: recent academic research shows that existing safety mechanisms are not yet robust against sophisticated prompt‑based attacks in real agentic systems. Some models accept malicious instructions or misinterpret input in ways that can cause incorrect tool use.
Integration and interoperability gaps: autonomous task execution often depends on plugin or tool ecosystems that are still immature. As a result, agents still need human confirmations far more often than ideal.
Context limits, though expanding rapidly (some models now process millions of tokens), still fall short of true continuous multi‑session memory without clever summarization strategies.
Which Agent Is Best for Which Use Case?
Best for deep research and knowledge workflows: ChatGPT. Its conversational reasoning, context retention, and integration with plugins make it ideal for complex analytical tasks.
Best for structured productivity and automation: Claude. It leads in coding, structured planning, and emerging desktop/browser automation with tools like Cowork.
Best for multimodal understanding and real‑time data: Gemini. Its multimodal reasoning and search integration make it best for tasks requiring up‑to‑date information combined with image/video/audio inputs.
Best for creative writing and narrative tasks: Claude and ChatGPT often tie here — Claude for structured drafting and ChatGPT for expressive, conversational flows.
Best for coding and developer workflows: Claude Opus 4.5 currently edges out competition on specific benchmarks, but Gemini and GPT have their own strengths depending on language and domain.
Conclusion: A Strategic Recommendation
All three of the leading AI systems are impressively powerful, but they are not identical, and the “best” choice depends on context.
For knowledge workers and analysts, ChatGPT is the most reliable and flexible because of its deep reasoning and strong plugin ecosystem.
For developers and structured automation use, Claude’s newest releases show clear advantages, especially in code generation and multi‑step planning.
For multimodal workflows and real‑time information needs, Gemini’s integration with Google Search and native image/video understanding is unmatched.
In the coming year, we can expect these agents to become more autonomous, more secure, and more capable of end‑to‑end task execution without human intervention. The frontier will likely shift toward hybrid systems that combine the best of structured reasoning, multimodal understanding, and safe autonomous action.

I started this research with one question in mind: Which image generation model gives creators the best combination of speed, accuracy, quality, and reliability? Although there’s a lot of buzz around new entrants and fast-growing models, four names consistently surfaced in benchmark leaderboards, professional user feedback, and my own tests: OpenAI’s GPT-4o Image Generation, Google’s Imagen 4, Midjourney (v7), and Stable Diffusion 3 / SDXL.
Each of these models embodies a different philosophy. GPT-4o aims for precision and general-purpose strength, Imagen targets photorealism and raw visual fidelity, Midjourney prioritizes artistic depth, and Stable Diffusion emphasizes customizability and openness. While much of the existing data comes from public comparisons and community testing rather than controlled lab conditions, a coherent picture emerges once you stack benchmarks and subjective experience side by side.
Image Creation Speed
When I started timing these systems, speed quickly revealed itself as more than just “how fast an image appears.” It actually interacts with UX (user waiting time), cost (API latency and throughput), and workflow efficiency — especially for professionals generating images in volume.
Stable Diffusion 3 wins here on pure throughput. Because it can be run locally on consumer or enterprise hardware and be optimized aggressively (e.g., SDXL Turbo modes), it churns out standard-resolution images in as little as a few seconds where infrastructure permits. When hosted in cloud environments with dedicated GPUs, its speed advantage becomes dramatic compared to the competitors. Benchmarks from community tests show Stable Diffusion generating images significantly faster than cloud-bound systems when configured on high-end hardware.
Google Imagen 4 places second in speed benchmarks in 2025–2026 comparisons. Reports put its generation times slightly ahead of GPT-4o in standard resolution tasks — making it an excellent choice for workflows where throughput and realism are both critical.
OpenAI’s GPT-4o Image Generation (including GPT Image models) sits in the middle. It does not beat local deployments of Stable Diffusion in raw seconds per image, but among cloud APIs with enterprise safety and high accuracy, it’s highly efficient. Published comparisons list it as competitive with Imagen 4, with performance optimized for large image batches, multi-object scenes, and API pipeline throughput.
Midjourney v7 lands at the back in raw latency. Because it’s typically accessed through Discord or web interfaces and balanced for visual exploration rather than pure speed, its latency is higher (often noticeable when generating multiple images). However, this is partly by choice: Midjourney prioritizes compositional refinement and stylistic fidelity over milliseconds shaved off per request.
In summary for speed: if you need images now and many of them, go Stable Diffusion 3 first, Imagen 4 second, GPT-4o third, and Midjourney fourth. The difference means tangible workflow efficiency for high-volume tasks.
Image Quality: Objective Metrics and Subjective Depth
Image quality is where things get nuanced. Raw metrics like FID (Fréchet Inception Distance) or human evaluation scores only tell part of the story. So I separated quality into photorealism, artistic expressiveness, and prompt fidelity.
For photorealism and objective fidelity, benchmarks in late 2025 place Imagen 4 at or near the top among leading image models. It produces highly realistic textures, accurate lighting, and detailed scenes with minimal artifacts. Its outputs are consistently rated high in human evaluations that examine realism and detail.
Closely behind is OpenAI’s GPT-4o Image Generation. Across test cases involving structured scenes, textual inscriptions, and complex object interactions, GPT-4o generative outputs score extremely well on both human and automated benchmarks. Many users report that GPT-4o’s images look “technically complete” with strong adherence to prompt specifics and realistic spatial relationships.
For artistic expressiveness and creative depth, Midjourney v7 is our clear winner. Though less focused on photorealism, it consistently excels at composition, lighting choices, color palettes, and stylistic coherence. Time and again, Midjourney images have been described as “visually compelling” and “gallery-ready,” favoring aesthetic impact over literal interpretation.
Stable Diffusion 3 has a slightly different profile. Its base outputs can vary depending on the specific model checkpoint and conditioning — a feature I’ll revisit in the control section — but it can match or even surpass closed models with adequate fine-tuning. Its strength lies in configurability. Without curation, its out-of-the-box images may lag slightly behind the others in raw polish, but with the right conditioning (ControlNet, LoRA, or fine-tuning layers), it can compete in both photorealism and artistic richness.
So if you define “quality” as photorealistic and prompt-faithful outputs, then Imagen 4 ranks first, GPT-4o second, Midjourney third (for photorealism), and Stable Diffusion fourth — unless you customize it, in which case it can rise to challenge the leaders in either category.
Ease of Prompting and Prompt Fidelity
This dimension often matters more than speed or even quality for many users because a model that “gets” your ideas quickly is worth far more in creative workflows.
I tested each model with layered, complex prompts — requiring multiple objects, actions, spatial relationships, and desired artistic styles. Here’s what I found:
GPT-4o Image Generation shines in prompt understanding. Its language model roots make complex prompt parsing very robust. For intricate requirements — like “a mid-century modern living room with photorealistic lighting, a golden retriever lounging on a velvet sofa, and surrealist shadows reflecting a Dalí influence” — GPT-4o reliably parses intent, spatial dependencies, and style. It often generates outputs that precisely reflect these nuances without extensive iteration.
Imagen 4 also does very well with complex prompts, specifically where clarity and detail are essential. Its photorealistic emphasis comes with strong semantic understanding of prompt descriptors, nouns, and adjectives. Very intricate environmental descriptors or high-detail textual instructions are usually executed faithfully.
Midjourney is a bit different. While it interprets prompts effectively, users often need to learn its style cues and preference tokens to get exactly what they want. Midjourney’s prompt grammar — sometimes involving style keywords, modifiers, and Discord-specific syntax — influences output heavily. Once you know how to “speak Midjourney,” its expressiveness is remarkable, but the learning curve is steeper compared to GPT-4o or Imagen.
Stable Diffusion is the most flexible — and the hardest to master. Because you can condition it with auxiliary tools (ControlNet, custom LoRA models, embedding tweaks), it can obey prompts extremely well once fine-tuned. But for average users without experience in prompt engineering or model conditioning, getting precise outputs often requires more iterations. Out of the box, prompt fidelity is good, but expertise unlocks its real potential.
So for ease of prompting: GPT-4o claims the first spot, Imagen 4 second, Midjourney third (after mastering its syntax), and Stable Diffusion fourth in terms of immediate out-of-box fidelity.
Continuity and Multi-Image Consistency
One of the trickiest tests I ran was generating a coherent set of images featuring the same character in multiple scenes. Many applications — concept art, character design, visual storytelling — depend on continuity.
Stable Diffusion, because of its open-source nature, pulls ahead here when you use techniques like embedding vectors, ControlNet pose conditioning, or character-specific LoRAs. Once the model “learns” a character, it can generate coherent variations because you can save and reuse character embeddings or fine-tune it on a small dataset. For continuity challenges, this configurability makes Stable Diffusion the best practical tool, even if it requires extra setup.
Midjourney does well too, but with caveats. It doesn’t yet offer the same depth of persistent identity control as bespoke embeddings in Stable Diffusion, but prompt chaining and consistent style tokens often produce recognizable continuity across images. It’s easier than without control, but still not as explicit as Stable Diffusion’s mechanisms.
GPT-4o Image Generation can maintain some consistency if prompts are carefully written with reiterated identifiers, but it tends to prioritize prompt interpretation over strict character persistence. It’s good — but not ideal — for continuity without external tooling.
Imagen 4, while excellent at single high-quality outputs, does not yet offer dedicated continuity features in standard UX workflows. It’s possible to coax consistent style references, but it’s less repeatable than Stable Diffusion’s saved embeddings or Midjourney’s prompt chaining.
In continuity ranking: Stable Diffusion first (with conditioning), Midjourney second, GPT-4o third, and Imagen 4 fourth.
Additional Dimensions That Matter
Beyond those primary categories, I explored control and customization, cost, ecosystem and tooling, deployment options, and community support — elements that often decide real-world adoption.
Control & Customization
Stable Diffusion is unrivaled here. With an open-source foundation, users build bespoke models, conditioners, and workflows — from facial consistency to specialized artistic styles.
Midjourney offers style parameters and creative controls, but it’s not open-ended like Stable Diffusion’s ecosystem.
GPT-4o provides robust prompt logic and structured output capabilities, but customization beyond prompt engineering is limited by its API and closed nature.
Imagen 4 has strong internal capabilities, but limited user-accessible adapters for deep customization right now.
Cost
Raw cost varies dramatically by use case. Local Stable Diffusion is essentially hardware-dependent, potentially cheaper than paid services once you have GPUs. Cloud APIs (GPT-4o, Imagen 4) charge per image or compute unit. Midjourney uses a subscription pricing model.
Stable Diffusion offers the best cost per image at scale if self-hosted.
Conclusions: Which Model Wins in Each Category?
I’ll state conclusions clearly, backed by the data and qualitative experience.
For image creation speed, Stable Diffusion 3 was fastest, Imagen 4 second, GPT-4o third, Midjourney fourth.
For raw image quality (photorealism), Imagen 4 led, GPT-4o followed, Midjourney excelled in style, and Stable Diffusion trailed until customized.
For prompt fidelity and ease, GPT-4o was best, Imagen 4 second, Midjourney third, Stable Diffusion fourth without prior conditioning.
For continuity and character consistency, Stable Diffusion (with tooling) led, Midjourney second, GPT-4o third, Imagen 4 fourth.
For control and customization, Stable Diffusion was unmatched, followed by Midjourney, GPT-4o, then Imagen 4.
What This Means for Users
No single model dominates every category — and that’s why today’s creators often blend tools. For concept art and expressive visuals, Midjourney still shines. For photorealistic, detail-rich tasks, Imagen 4 is compelling. For precision and prompt compliance, GPT-4o is hard to beat. And for deep control, continuity, and scalable workflows, Stable Diffusion is indispensable.
The space is evolving rapidly, and new entrants (like emerging models such as Nano Banana or FLUX) are challenging the status quo. But the evidence from benchmarks and real-world use makes one architecturally clear division: closed-source models excel in out-of-box quality and prompt comprehension, while open-source models dominate in flexibility and scalability.
If you’d like, I can produce a second part with example prompts and visual comparisons, or tailor this for a specific audience such as marketers, game developers, or academic researchers.

In the world of artificial intelligence, the dazzling breakthroughs often come from the intersection of scale, creativity and a willingness to rethink long‑held assumptions. Meta AI’s DINO and SAM models embody all of these qualities, pushing computer vision beyond incremental gains and toward a future in which machines perceive and interact with the visual world not as coded rules or rigid categories, but with nuanced, flexible and context‑aware understanding. Together, these models represent a broader trend in AI research: moving from narrow, supervised systems toward general, adaptable vision systems that can be applied to problems ranging from everyday image processing to life‑critical applications like autonomous medical triage.
Understanding how these models work, why they matter, and where they are heading requires unpacking both the technical innovations behind them and the real‑world problems they are being used to solve. This article explores that trajectory — from the self‑supervised foundations of DINO to the promptable segmentation of SAM, the integration of these models into cutting‑edge robotics and emergency response systems, and the broader implications for industries reliant on visual intelligence.
The Limits of Traditional Computer Vision — and the Promise of a New Approach
For decades, computer vision systems depended on large labeled datasets and handcrafted pipelines. Engineers painstakingly annotated millions of images with categories — “cat,” “car,” “tree” — and models were trained to recognize these labels. This approach powered early breakthroughs, from facial recognition to autonomous driving research, but it has clear limitations. Labeling is expensive, slow and inherently constrained by the categories humans choose in advance.
Moreover, traditional supervised learning struggles when confronted with tasks or domains that deviate from its training data: medical images, satellite imagery, robotic perception in unstructured environments and scenes with unusual objects all pose significant challenges. Models trained to recognize a fixed set of classes simply cannot adapt to new objects or contexts without large amounts of additional data and retraining.
Meta AI’s DINO and SAM forge a new path, emphasizing models that learn from data without labels and interact with visual content in more flexible ways. These aren’t specialized tools for a single task — they are foundation models for vision, designed to support a wide array of downstream applications.
DINO: Seeing Without Labels
At its core, DINO (short for distillation with no labels) is a self‑supervised learning (SSL) technique. Unlike traditional models that learn from human‑curated annotations, DINO learns from the structure of images themselves. During training, the model receives multiple “views” of the same image — for example, two different random crops — and learns to produce similar visual representations for both. A “teacher” network guides a “student” network, helping it develop a rich internal understanding of visual concepts without ever being told what objects are.
This form of learning yields several advantages. First, it dramatically reduces the reliance on labeled data — a perennial bottleneck in computer vision. Second, the representations DINO learns are general and versatile: they can support classification, depth estimation, segmentation and other tasks, often with minimal fine‑tuning. This is why DINO and its successors, like DINOv2 and DINOv3, are considered universal vision backbones.
In practice, DINO’s output is a feature embedding — a vector representation of an image that captures its semantic and structural essence. These embeddings can then be used by other algorithms or models to perform high‑level tasks. At scale, the latest versions of DINO, trained on hundreds of millions of images, produce visual representations that rival or even surpass supervised alternatives in many domains.
This ability to learn without labels isn’t just a convenience for data scientists; it’s a fundamental shift in how AI perceives the world. Instead of relying on explicit human instruction, the model learns from the inherent patterns and similarities in the visual world itself — a more scalable and, arguably, more human‑like approach to learning.
SAM: Promptable Segmentation for Any Object
If DINO provides the vision backbone, SAM — the Segment Anything Model — is the interface that allows flexible interaction with visual content. Traditional segmentation models are trained for specific tasks, like identifying people or cars. SAM, by contrast, is designed to segment any object, on demand.
What makes SAM revolutionary is its promptability. Users can provide simple cues — a click on the object, a bounding box, a rough sketch, even text prompts — and the model will generate a pixel‑accurate mask for the object or region of interest. The result is a model that can be integrated into interactive annotation workflows, automated pipelines and multimodal systems that combine vision with language.
Early versions of SAM were limited to static images, but ongoing research and iterations (including SAM 2 and emerging SAM 3 architectures) are expanding its capabilities to video segmentation, prompt‑able concept segmentation and even cognitive interpretation of scenes. Unlike rigid segmentation systems, SAM doesn’t require predefined classes — instead, it responds to prompts, making it far more adaptable.
In computer vision, segmentation is a foundational task. Whether you’re distinguishing a tumor from healthy tissue in a medical scan, isolating a car in autonomous driving footage or extracting a product from a cluttered e‑commerce image, segmentation determines how well a system perceives the elements of a scene. By democratizing segmentation with prompts, SAM shifts power from rigid pipelines to flexible, human‑in‑the‑loop models.
How DINO and SAM Work Together — and Beyond
Individually, DINO and SAM are powerful. Combined, they unlock even richer capabilities. One compelling example of this synergy is the integration of Grounding DINO, an open‑vocabulary detection model that leverages natural language to guide object identification, with SAM’s segmentation. In this pipeline, Grounding DINO first identifies regions of interest using textual cues like “wound?” or “blood?”, and SAM then segments those regions with pixel precision.
This combination is more than an academic exercise; it’s part of real‑world systems being deployed today.
From Research to Real‑World Impact: The DARPA Triage Challenge
High‑stakes environments like disaster response and emergency medicine have long been testbeds for cutting‑edge AI research. The DARPA Triage Challenge, a multi‑year competition launched by the U.S. Defense Advanced Research Projects Agency, aims to transform autonomous medical triage using robotics and AI systems that can operate in chaotic, low‑connectivity environments with dust, darkness, explosions and other sensory degradations.
One standout participant, the PRONTO team from the University of Pennsylvania, combines autonomous drones and ground robots with Meta AI’s DINO, SAM and Grounding DINO models to rapidly assess casualties and physiological signs without human contact. In simulated mass casualty incidents, these systems process visual data in real time, segmenting victims, identifying wounds and estimating vital signs like heart rate and respiration. All of this information is visualized for first responders, enabling prioritization of limited resources — a critical advantage when seconds matter.
This isn’t a distant dream — Phase 1 of the DARPA Triage Challenge in 2024 already demonstrated the potential for such systems to operate in complex, degraded environments. As the challenge progresses, the continued evolution of DINO and SAM — alongside robotics and sensor technologies — could reshape how medical teams respond to disasters worldwide.
Why These Models Matter Beyond Academia
While the triage challenge is a striking example, the implications of DINO and SAM extend far beyond emergency response. Both models are part of a larger shift in AI toward foundation models that serve as flexible building blocks across domains.
Consider the implications for:
Robotics: Robotic perception has historically been limited by rigid, task‑specific vision systems. With DINO and SAM, robots can interpret scenes more flexibly, segmenting objects on demand and adapting to unstructured environments — a foundational requirement for true autonomy.
Augmented Reality (AR) and Mixed Reality: AR systems require rapid, accurate understanding of real‑world scenes. Promptable segmentation enables AR overlays that align precisely with physical objects, while DINO’s general representations support context‑aware interactions.
Healthcare Imaging: Medical imaging often faces data scarcity and domain shifts that stump traditional models. The ability to segment and analyze medical scans with minimal task‑specific training could democratize access to advanced diagnostics and reduce reliance on large labeled datasets.
Satellite and Aerial Imagery: Earth observation poses similar challenges: diverse object types, changing light and weather conditions, and limited annotations. SAM’s general segmentation and DINO’s robust features can support automated analysis for agriculture, urban planning and environmental monitoring.
Creative Tools and Content Production: Content creators in film, gaming and digital art rely on visual tools to isolate, edit and manipulate imagery. Promptable segmentation democratizes what once required manual masking and expensive software.
Challenges and the Road Ahead
Despite their transformative potential, DINO and SAM are not magic bullets. They face limitations — segmentation models may struggle with highly specialized medical imagery without fine‑tuning, and dense feature extraction can be computationally intensive. Ethical concerns around privacy, bias in training data, and misuse of vision technologies also loom large.
Moreover, the integration of vision with language and reasoning — while advancing rapidly — remains an open frontier. Emerging research, including generative vision models and multi‑modal reasoning systems, will likely integrate with or build upon the foundations laid by DINO and SAM.
Conclusion: A New Paradigm for Visual Intelligence
Meta AI’s DINO and SAM models represent more than technical achievements; they mark a shift in how we build and interact with vision systems. By learning from unlabeled data and enabling prompt‑based interaction with visual content, these models move us toward a future in which machines see not through narrow labels but through general, adaptable understanding.
The implications — from autonomous robots in disaster zones to everyday tools that make imagery more accessible — are profound. As research continues and these models evolve, they promise to bring the power of visual intelligence to industries and applications once considered out of reach for AI.
-

 AI Model6 months ago
AI Model6 months agoTutorial: How to Enable and Use ChatGPT’s New Agent Functionality and Create Reusable Prompts
-

 AI Model4 months ago
AI Model4 months agoHow to Use Sora 2: The Complete Guide to Text‑to‑Video Magic
-

 AI Model5 months ago
AI Model5 months agoTutorial: Mastering Painting Images with Grok Imagine
-

 AI Model7 months ago
AI Model7 months agoMastering Visual Storytelling with DALL·E 3: A Professional Guide to Advanced Image Generation
-

 Tutorial4 months ago
Tutorial4 months agoFrom Assistant to Agent: How to Use ChatGPT Agent Mode, Step by Step
-

 AI Model9 months ago
AI Model9 months agoGrok: DeepSearch vs. Think Mode – When to Use Each
-

 News4 months ago
News4 months agoOpenAI’s Bold Bet: A TikTok‑Style App with Sora 2 at Its Core
-
AI Model9 months ago
Crafting Effective Prompts: Unlocking Grok’s Full Potential