
Education
Perceptrons: The Cornerstone of Modern AI
- Share
- Tweet /data/web/virtuals/375883/virtual/www/domains/spaisee.com/wp-content/plugins/mvp-social-buttons/mvp-social-buttons.php on line 63
https://spaisee.com/wp-content/uploads/2025/05/edu2-1.jpg&description=Perceptrons: The Cornerstone of Modern AI', 'pinterestShare', 'width=750,height=350'); return false;" title="Pin This Post">
Perceptrons are foundational units in the architecture of neural networks and are essential to understanding how modern artificial intelligence (AI) models function. Introduced by Frank Rosenblatt in 1958, the perceptron was one of the first algorithms capable of performing supervised learning. Although simplistic, it introduced the key concepts of weight adjustment, thresholding, and data-driven decision-making that are still at the core of AI systems today.
This article is designed for IT professionals and students with a general understanding of data structures, linear algebra, and system architecture. It aims to explain perceptrons in technical, yet approachable terms without requiring programming expertise.
What Is a Perceptron?
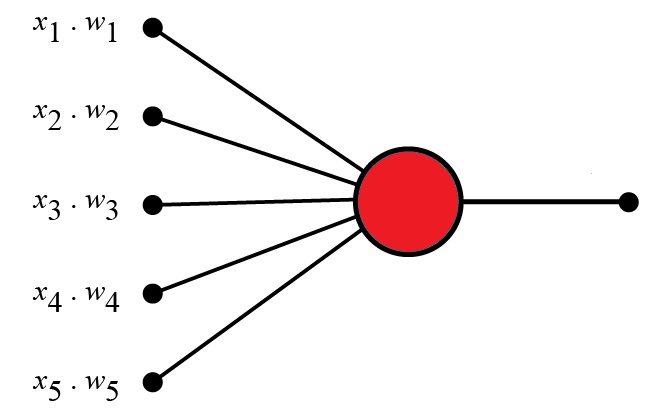
A perceptron is a type of binary classifier that maps an input vector to an output value of either 0 or 1. Conceptually, it’s a computational model of a biological neuron, where each input is multiplied by a weight, summed, and then passed through an activation function.
The perceptron operates by evaluating whether the weighted sum of inputs exceeds a certain threshold. If it does, it outputs a 1 (active); otherwise, it outputs a 0 (inactive).
Components:
- Inputs (features): Numerical values representing measurable characteristics of data.
- Weights: Parameters that determine the influence of each input.
- Bias: A constant added to shift the activation function’s threshold.
- Activation Function: Typically, a step function for basic models, it determines the binary outcome.
Understanding Linear Separability
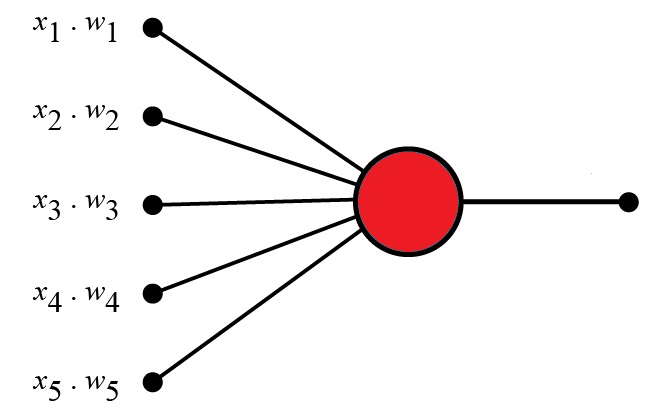
A single-layer perceptron can only correctly classify data that is linearly separable. This means that the data classes can be divided by a straight line (or a hyperplane in higher dimensions).
Suitable for:
- Logical operations like AND, OR
Not suitable for:
- Nonlinear functions like XOR (which led to significant criticism in early AI research)
This limitation prompted the development of multi-layer perceptrons (MLPs), which can solve more complex, nonlinear problems.
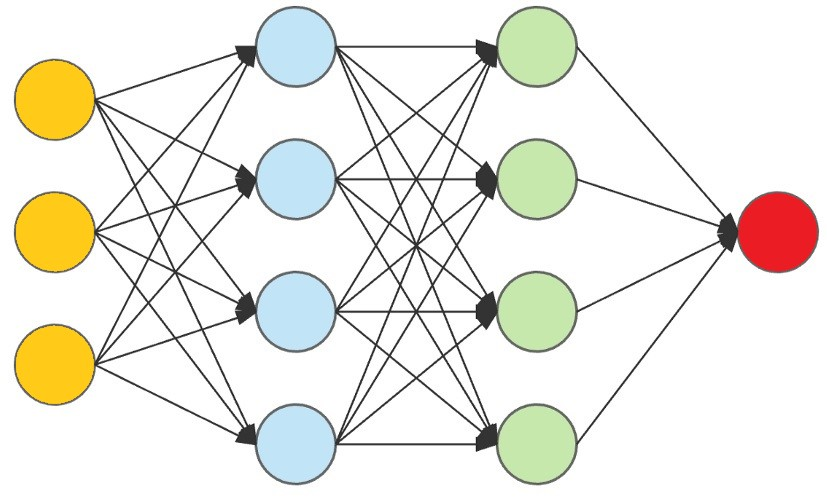
Multi-Layer Perceptrons (MLPs)
MLPs are networks of perceptrons organized into layers:
- Input Layer: Accepts the initial features.
- Hidden Layer(s): Introduces non-linearity via activation functions like ReLU, Sigmoid, or Tanh.
- Output Layer: Provides the final classification or regression output.
MLPs can approximate any continuous function when configured with sufficient depth and complexity. This makes them the basis for more advanced deep learning models.
The Learning Process
Perceptrons learn by adjusting weights based on the error in prediction. This process is iterative and aims to reduce the discrepancy between predicted and actual values.
Steps in the Learning Process:
- Calculate the weighted sum of inputs and bias.
- Apply the activation function.
- Compare the result to the expected output.
- Update the weights and bias if there’s an error.
The adjustments are guided by a parameter called the learning rate, which controls how much weights change in response to errors. This process is repeated across the training dataset until the perceptron reaches acceptable accuracy.
In MLPs, the learning process is governed by backpropagation, where errors are propagated backward from the output layer to the input layer, adjusting weights layer by layer using techniques like gradient descent.
Real-World Applications
Perceptrons and MLPs are used in a wide range of applications where pattern recognition and classification are required:
- Spam Filtering: Classify emails based on the presence of keywords, structure, and sender patterns.
- Financial Forecasting: Assess credit risk or predict stock trends using customer profiles and market indicators.
- Medical Diagnosis: Analyze symptoms and patient data to identify likely diseases.
- Image Recognition: Classify images by detecting features and patterns (e.g., facial recognition).
- Industrial Automation: Predict equipment failures based on sensor data.
While simple perceptrons are no longer sufficient for complex tasks, they remain conceptually important and serve as the building blocks of more advanced architectures.
From Perceptrons to Deep Learning
Modern AI systems are often composed of deep architectures like:
- Convolutional Neural Networks (CNNs): Specialized for image and spatial data.
- Recurrent Neural Networks (RNNs): Designed for sequential data such as time series or language.
- Transformers: State-of-the-art models in natural language processing that use self-attention mechanisms.
All of these models build upon the core concept of the perceptron: learning representations from data through weighted connections and threshold-based decision-making.
Key Limitations and Considerations
1. Interpretability: As networks grow deeper, understanding their internal decision-making becomes challenging. Simple perceptrons are easy to inspect, but deep networks often act as “black boxes.”
2. Computation Cost: Training large networks is resource-intensive, requiring powerful hardware like GPUs or TPUs.
3. Data Requirements: Perceptrons need labeled data for supervised learning. Poor data quality or insufficient data can significantly affect performance.
4. Overfitting: With too many parameters, a network might memorize the training data instead of learning general patterns. Regularization and dropout techniques are often used to mitigate this.
Conclusion: A Simple Yet Powerful Idea
The perceptron represents the genesis of neural computation. Despite its limitations, it introduced fundamental concepts such as:
- Weight optimization
- Decision thresholds
- Learning from feedback
Understanding perceptrons gives insight into the design logic of more complex neural networks. For IT professionals, this foundation is essential to grasp the structure and function of modern AI models. As AI continues to evolve, revisiting its simplest form can still offer a valuable perspective.













Capabilities Advancing, but the World Stays the Same
In a post shared recently by Sam Altman, OpenAI laid out a new framework reflecting just how far artificial intelligence has come — and how far the company believes we have yet to go. The essay begins with the recognition that AI systems today are performing at levels unimaginable only a few years ago: they’re solving problems humans once thought required deep expertise, and doing so at dramatically falling cost. At the same time, OpenAI warns that the gap between what AI is capable of and what society is actually experiencing remains vast.
OpenAI describes recent AI progress as more than incremental. Tasks that once required hours of human effort can now be done by machines in minutes. Costs of achieving a given level of “intelligence” from AI models are plummeting — OpenAI estimates a roughly forty-fold annual decline in cost for equivalent capability. Yet while the technology has advanced rapidly, everyday life for most people remains largely unchanged. The company argues that this reflects both the inertia of existing systems and the challenge of weaving advanced tools into the fabric of society.
Looking Ahead: What’s Next and What to Expect
OpenAI forecasts that by 2026 AI systems will be capable of “very small discoveries” — innovations that push beyond merely making human work more efficient. By 2028 and beyond, the company believes we are likely to see systems that can make even more significant discoveries — though it acknowledges the uncertainties inherent in such predictions. The post also underscores that the future of AI is not just about smarter algorithms, but about shaped social, economic and institutional responses.
A Framework for Responsible Progress
The document outlines three major pillars that OpenAI deems essential for navigating the AI transition responsibly. First, labs working at the frontier must establish shared standards, disclose safety research, and coordinate to avoid destructive “arms-race” dynamics. In OpenAI’s view, this is akin to how building codes and fire standards emerged in prior eras.
Second, there must be public oversight and accountability aligned with the capabilities of the technology — meaning that regulations and institutional frameworks must evolve in concert with rising AI power. OpenAI presents two scenarios: one in which AI evolves in a “normal” mode and traditional regulatory tools suffice, the other in which self-improving or super-intelligent systems behave in novel ways and demand new approaches.
Third, the concept of an “AI resilience ecosystem” is introduced — a system of infrastructure, monitoring, response teams and tools, analogous to the cybersecurity ecosystem developed around the internet. OpenAI believes such resilience will be crucial regardless of how fast or slow AI evolves.
Societal Impact and Individual Empowerment
Underlying the vision is the belief that AI should not merely make things cheaper or faster, but broaden access and improve lives. OpenAI expects AI to play major roles in fields like healthcare diagnostics, materials science, climate modeling and personalized education — and aims for advanced AI tools to become as ubiquitous as electricity, clean water or connectivity. However, the transition will be uneven and may strain the socioeconomic contract: jobs will change, institutions may be tested, and we may face hard trade-offs in distribution of benefit.
Why It Matters
This statement represents a turning point — not just for OpenAI, but for the AI ecosystem broadly. It signals that leading voices are shifting from what can AI do to how should AI be governed, deployed and embedded in society. For investors, policy-makers and technologists alike, the message is clear: the existence of powerful tools is no longer the question. The real question is how to capture their upside while preventing cascading risk.
In short, OpenAI is saying: yes, AI is now extremely capable and moving fast. But the institutions, policies and social frameworks around it are still catching up. The coming years are not just about brighter tools — they’re about smarter integration. And for anyone watching the next phase of generative AI, this document offers a foundational lens.

Everyone wants an AI that tells the truth. But the reality is — not all AI outputs are created equal. Whether you’re using ChatGPT, Claude, or Gemini, the precision of your answers depends far more on how you ask than what you ask. After months of testing, here’s a simple “six-level scale” that shows what separates a mediocre chatbot from a research-grade reasoning engine.
Level 1 — The Basic Chat
The weakest results come from doing the simplest thing: just asking.
By default, ChatGPT uses its Instant or fast-response mode — quick, but not very precise. It generates plausible text rather than verified facts. Great for brainstorming, terrible for truth.
Level 2 — The Role-Play Upgrade
Results improve dramatically if you use the “role play” trick. Start your prompt with something like:
“You are an expert in… and a Harvard professor…”
Studies confirm this framing effect boosts factual recall and reasoning accuracy. You’re not changing the model’s knowledge — just focusing its reasoning style and tone.
Level 3 — Connect to the Internet
Want better accuracy? Turn on web access.
Without it, AI relies on training data that might be months (or years) old.
With browsing enabled, it can pull current information and cross-check claims. This simple switch often cuts hallucination rates in half.
Level 4 — Use a Reasoning Model
This is where things get serious.
ChatGPT’s Thinking or Reasoning mode takes longer to respond, but its answers rival graduate-level logic. These models don’t just autocomplete text — they reason step by step before producing a response. Expect slower replies but vastly better reliability.
Level 5 — The Power Combo
For most advanced users, this is the sweet spot:
combine role play (2) + web access (3) + reasoning mode (4).
This stack produces nuanced, sourced, and deeply logical answers — what most people call “AI that finally makes sense.”
Level 6 — Deep Research Mode
This is the top tier.
Activate agent-based deep research, and the AI doesn’t just answer — it works. For 20–30 minutes, it collects, verifies, and synthesizes information into a report that can run 10–15 pages, complete with citations.
It’s the closest thing to a true digital researcher available today.
Is It Perfect?
Still no — and maybe never will be.
If Level 1 feels like getting an answer from a student doing their best guess, then Level 4 behaves like a well-trained expert, and Level 6 performs like a full research team verifying every claim. Each step adds rigor, depth, and fewer mistakes — at the cost of more time.
The Real Takeaway
When people say “AI is dumb,” they’re usually stuck at Level 1.
Use the higher-order modes — especially Levels 5 and 6 — and you’ll see something different: an AI that reasons, cites, and argues with near-academic depth.
If truth matters, don’t just ask AI — teach it how to think.

In 2025, millions rely on AI chatbots for breaking news and current affairs. Yet new independent research shows these tools frequently distort the facts. A European Broadcasting Union (EBU) and BBC–supported study found that 45% of AI-generated news answers contained significant errors, and 81% had at least one factual or contextual mistake. Google’s Gemini performed the worst, with sourcing errors in roughly 72% of its responses. The finding underscores a growing concern: the more fluent these systems become, the harder it is to spot when they’re wrong.
Hallucination by Design
The errors aren’t random; they stem from how language models are built. Chatbots don’t “know” facts—they generate text statistically consistent with their training data. When data is missing or ambiguous, they hallucinate—creating confident but unverified information.
Researchers from Reuters, the Guardian, and academic labs note that models optimized for plausibility will always risk misleading users when asked about evolving or factual topics.
This pattern isn’t new. In healthcare tests, large models fabricated medical citations from real journals, while political misinformation studies show chatbots can repeat seeded propaganda from online data.
Why Chatbots “Lie”
AI systems don’t lie intentionally. They lack intent. But their architecture guarantees output that looks right even when it isn’t. Major causes include:
- Ungrounded generation: Most models generate text from patterns rather than verified data.
- Outdated or biased training sets: Many systems draw from pre-2024 web archives.
- Optimization for fluency over accuracy: Smooth answers rank higher than hesitant ones.
- Data poisoning: Malicious actors can seed misleading information into web sources used for training.
As one AI researcher summarized: “They don’t lie like people do—they just don’t know when they’re wrong.”
Real-World Consequences
- Public trust erosion: Users exposed to polished but false summaries begin doubting all media, not just the AI.
- Amplified misinformation: Wrong answers are often screenshot, shared, and repeated without correction.
- Sector-specific risks: In medicine, law, or finance, fabricated details can cause real-world damage. Legal cases have already cited AI-invented precedents.
- Manipulation threat: Adversarial groups can fine-tune open models to deliver targeted disinformation at scale.
How Big Is the Problem?
While accuracy metrics are worrying, impact on audiences remains under study. Some researchers argue the fears are overstated—many users still cross-check facts. Yet the speed and confidence of AI answers make misinformation harder to detect. In social feeds, the distinction between AI-generated summaries and verified reporting often vanishes within minutes.
What Should Change
- Transparency: Developers should disclose when responses draw from AI rather than direct source retrieval.
- Grounding & citations: Chatbots need verified databases and timestamped links, not “estimated” facts.
- User literacy: Treat AI summaries like unverified tips—always confirm with original outlets.
- Regulation: Oversight may be necessary to prevent automated systems from impersonating legitimate news.
The Bottom Line
The 81% error rate is not an isolated glitch—it’s a structural outcome of how generative AI works today. Chatbots are optimized for fluency, not truth. Until grounding and retrieval improve, AI remains a capable assistant but an unreliable journalist.
For now, think of your chatbot as a junior reporter with infinite confidence and no editor.
-

 AI Model6 months ago
AI Model6 months agoTutorial: How to Enable and Use ChatGPT’s New Agent Functionality and Create Reusable Prompts
-

 AI Model4 months ago
AI Model4 months agoHow to Use Sora 2: The Complete Guide to Text‑to‑Video Magic
-

 AI Model5 months ago
AI Model5 months agoTutorial: Mastering Painting Images with Grok Imagine
-

 AI Model7 months ago
AI Model7 months agoComplete Guide to AI Image Generation Using DALL·E 3
-

 AI Model7 months ago
AI Model7 months agoMastering Visual Storytelling with DALL·E 3: A Professional Guide to Advanced Image Generation
-

 Tutorial4 months ago
Tutorial4 months agoFrom Assistant to Agent: How to Use ChatGPT Agent Mode, Step by Step
-

 AI Model9 months ago
AI Model9 months agoGrok: DeepSearch vs. Think Mode – When to Use Each
-

 News4 months ago
News4 months agoOpenAI’s Bold Bet: A TikTok‑Style App with Sora 2 at Its Core