



When Moonshot AI unveiled Kimi K2 in July 2025, the release sent shockwaves through the artificial intelligence community. Touted as the world’s first open-weight trillion-parameter Mixture-of-Experts...



Why Ask AI to Describe Images? In an age where AI-generated art, digital design, and prompt-based creativity are reshaping how we create visuals, the ability to...



Imagine transforming long-form content—podcasts, webinars, interviews—into scroll-stopping social clips with zero editing skills. That’s exactly what OpusClip delivers: an AI-powered tool designed to help creators, marketers,...



So, you’ve just opened up an AI tool like ChatGPT or another assistant, and you’re wondering what to type into that blank prompt box. You’re not...



Introduction Artificial Intelligence (AI) has become a buzzword in recent years—but for many, it’s still mysterious, intimidating, or just plain confusing. You may have heard about...



Have you ever wondered how your phone suggests the perfect song, how a game knows your next move, or how a robot vacuum avoids crashing into...
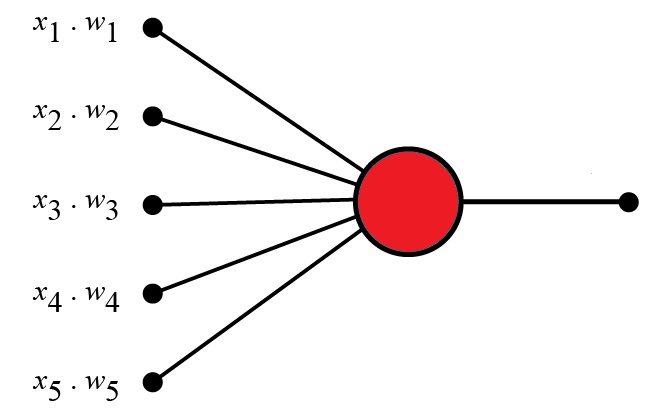
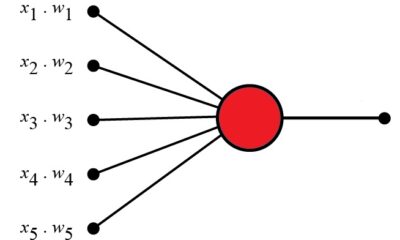
Perceptrons are foundational units in the architecture of neural networks and are essential to understanding how modern artificial intelligence (AI) models function. Introduced by Frank Rosenblatt...



Have you ever wondered how your phone can recognize your face or how Netflix knows exactly which show you’ll love next? It’s not magic—it’s machine learning!...