
AI Model
Complete Guide to AI Image Generation Using DALL·E 3

- Share
- Tweet /data/web/virtuals/375883/virtual/www/domains/spaisee.com/wp-content/plugins/mvp-social-buttons/mvp-social-buttons.php on line 63
https://spaisee.com/wp-content/uploads/2025/07/dragon2-1-1000x600.png&description=Complete Guide to AI Image Generation Using DALL·E 3', 'pinterestShare', 'width=750,height=350'); return false;" title="Pin This Post">
If you already know the basics of prompting, come join us to level up your skills with DALL·E 3.
In this tutorial, you’ll learn advanced techniques and creative tricks to generate stunning images with precision and style.
Section 0: Getting Started — Logging In and Accessing DALL·E
What is DALL·E 3?
DALL·E 3 is the latest image generation model by OpenAI, integrated directly into ChatGPT. It allows users to generate and edit images using natural language prompts.
Where to access it:
The most up-to-date version of DALL·E is available inside ChatGPT (https://chat.openai.com) for users with a ChatGPT Plus subscription.
Steps to log in and start generating images:
- Go to https://chat.openai.com
- Sign up or log in to your OpenAI account.
- Click your name or profile icon in the bottom left and go to Settings.
- Under “My Plan”, upgrade to ChatGPT Plus ($20/month).
- In the model switcher at the top, select GPT-4 (you’ll be using GPT-4o, which includes DALL·E 3).
- You’re now ready to generate images by typing prompts into the chat.
To generate an image, simply enter a prompt like this:
“Create an image of a castle floating in the clouds, digital painting style.”
ChatGPT will return the generated image directly in the conversation.

Section 1: The Fundamentals — How DALL·E Thinks
DALL·E is a language-to-image model. It doesn’t “see” or “imagine” like a human. It creates images by predicting visual outcomes based on text descriptions. That means it responds best to clear, descriptive language—especially language grounded in visual, artistic, and emotional cues.
To get great results, you must describe your scene as though explaining it to a professional illustrator or cinematographer.
Section 2: Structuring a Strong Image Prompt
To reliably control the results, write prompts that include specific visual attributes. The more you define the visual world, the less randomness DALL·E introduces.
Use this structure for your prompts:
[Subject] doing [Action], in [Setting/Environment], at [Time of Day], with [Lighting and Color], in the style of [Artist or Medium], conveying a [Mood or Emotion]
Example:
“A woman standing in a wheat field at sunset, with warm golden light, soft shadows, and a calm expression, in the style of an oil painting, evoking peace and nostalgia.”

Section 3: Visual Thinking — Moving from Concept to Prompt
Before writing, ask:
- What is the subject?
- What is the setting or environment?
- What emotion or atmosphere do I want to create?
- What style or medium should it look like?
- What kind of lighting and color palette would match?
Example Concept
Idea: “A sense of isolation in a futuristic world”
Step-by-step translation:
- Subject: A lone figure
- Environment: Dystopian cityscape
- Mood: Isolation
- Style: Sci-fi concept art
- Time and light: Night, glowing neon
Prompt:
“A lone figure walking down an empty neon-lit street in a futuristic city, deep shadows and glowing signs, night scene, cinematic sci-fi style, inspired by Blade Runner.”
This prompt tells DALL·E what to show, how it should feel, and what style to emulate.
Section 4: Controlling Style
DALL·E supports a wide range of styles. Naming a style in your prompt helps guide the composition, color, and texture of the image.
Common style terms you can use:
- Oil painting
- Watercolor
- Ink drawing
- Digital illustration
- 3D render
- Pixel art
- Retro comic book
- Cyberpunk
- Ukiyo-e (Japanese woodblock)
- Surrealism
- Art deco
- Minimalist line art
Example prompt:
“A giraffe wearing sunglasses walking through Times Square, in the style of a 1990s comic book cover.”

Why it works:
You’ve described the scene and given a visual reference style, which DALL·E can map to a specific type of color, texture, and composition.
Section 5: Iterating and Refining Prompts
Creating high-quality images with DALL·E is an iterative process. Your first image is a sketch. Each following prompts should refine or evolve it.
Start simple:
“A dragon flying over mountains.”
Add detail:
“A golden dragon flying above snow-covered mountains under a twilight sky, glowing clouds, fantasy illustration.”
Refine style and mood:
“A golden dragon soaring above icy mountains at dusk, wings reflecting orange light, cinematic fantasy art in the style of Magic: The Gathering card illustrations.”
Each refinement clarifies:
- Subject appearance
- Lighting
- Emotion
- Visual format
Section 6: Using Inpainting to Edit Images
DALL·E 3 (via ChatGPT Plus) supports inpainting, which allows you to change part of an image after it has been generated.
How to use inpainting:
- Generate an image with a prompt.
- Hover over the image in ChatGPT and click the “Edit” (pencil) icon.
- Use the brush to select the area you want to modify.
- Enter an instruction, such as “Replace the tree with a small pagoda.”
- DALL·E will regenerate just the selected area.
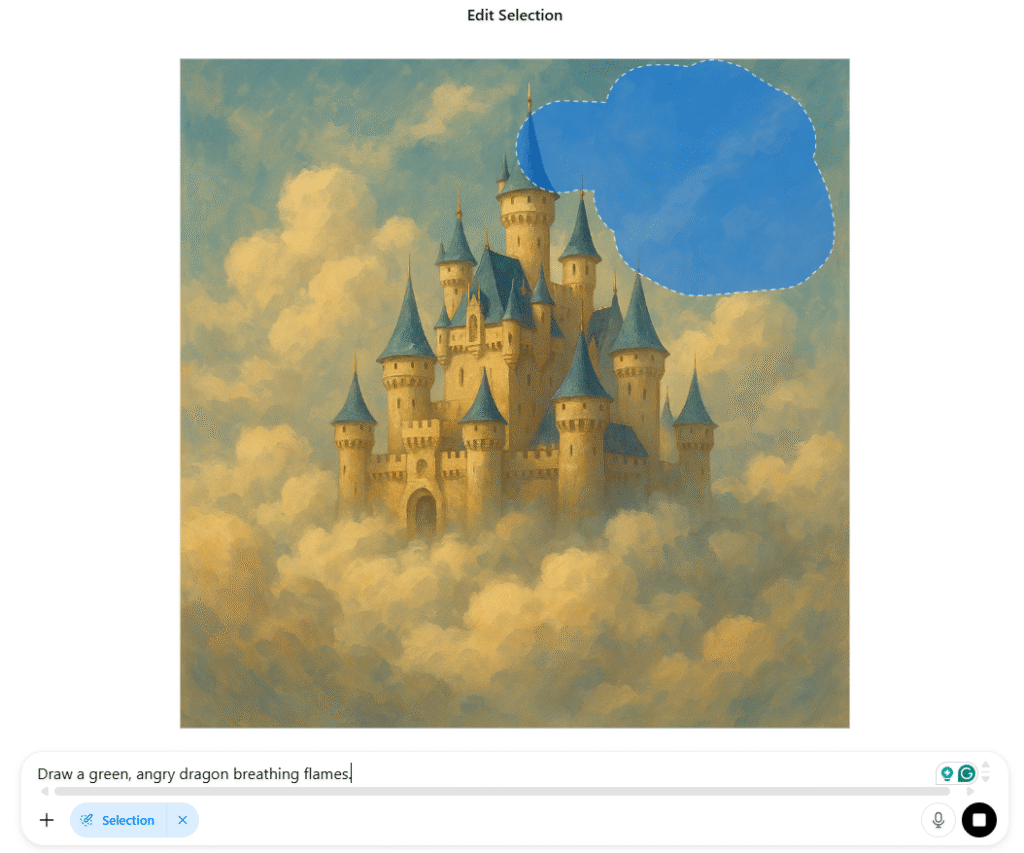
This is ideal for:
- Adding or removing elements
- Correcting details (lighting, faces, objects)
- Evolving a scene step-by-step
Section 7: Creating Custom Visual Styles
You can direct DALL·E to create unique visual styles by blending influences.
Example prompt:
“A cityscape rendered in a hybrid style combining Japanese ukiyo-e woodblock art and modern architectural sketching, monochrome with red accents.”

This kind of prompt works because it:
- Names two style references
- Specifies the medium and texture (woodblock + sketch)
- Introduces a color limitation (monochrome + red)
You can blend:
- Historical art styles with sci-fi
- Real-world cultural references with digital formats
- Natural textures with abstract design
Section 8: Composition and Directional Language
To further control the image, include composition cues. DALL·E understands basic photographic and cinematic language.
Terms to use:
- Wide shot / close-up
- Bird’s-eye view / top-down / isometric
- Symmetrical / centered / off-center
- Portrait orientation / landscape orientation
- Backlighting / front lighting / rim light / ambient light
- Mood words: eerie, joyful, tranquil, apocalyptic
Example prompt with composition:
“A child looking out a window at a rainy cityscape, viewed from behind, soft diffused lighting, shallow depth of field, photographic realism.”
Here, you’re directing the perspective, lighting, and style.
Section 9: Prompt Templates for Common Use Cases
Character Portrait
“A [type of person or creature], wearing [style or clothing], in [pose or expression], background of [environment], in the style of [artist or medium], with [lighting and mood].”
Example:
“A medieval knight in weathered armor, standing in profile against a stormy battlefield, realistic digital painting with dramatic lighting.”
Landscape
“A [landscape or environment], under [time of day and weather], seen from [angle], in the style of [painting or media], conveying a sense of [emotion or scale].”
Example:
“A vast desert at sunset, viewed from a high dune, shadows stretching far, soft orange and purple tones, in the style of a watercolor painting, evoking loneliness.”
Surreal Concept
“A [subject or object] in a world where [unusual twist], rendered in [style or medium], with [color palette and lighting], inspired by [surrealist artist or film].”
Example:
“An elephant made of clock gears walking across a frozen ocean, in the style of Salvador Dalí, with melting shadows and surreal lighting.”

Section 10: Ethical Use and Exporting Images
Saving and using images:
- Right-click on generated images to save.
- You are permitted to use DALL·E images for personal and commercial use under OpenAI’s terms.
- Avoid using generated images to impersonate real individuals or mislead others about authorship.
Things to avoid:
- Generating nudity, gore, or harmful content
- Trying to recreate real people’s likenesses
- Misusing AI art in misleading advertising or journalistic contexts
Section 11: Practice Challenge – Evolve a Prompt in 3 Steps
Starting prompt:
“A lighthouse on a cliff”
Refinement 1:
“A white lighthouse on a jagged cliff at sunset, waves crashing below, digital painting.”
Refinement 2:
“A towering white lighthouse on a crumbling cliff during a storm, lightning striking in the background, dramatic shadows, painted in 19th-century Romantic style.”
Refinement 3:
“A surreal scene of a lighthouse floating above the ocean, beams of light piercing the sky, oil on canvas style with bold brushstrokes, dreamlike atmosphere.”

This practice teaches:
- Prompt layering
- Mood shaping
- Style transitions
- Creative remixing
Summary
AI image generation is a creative process that rewards visual thinking, iteration, and control. To become proficient with DALL·E, you need to:
- Write descriptive, structured prompts
- Direct style, lighting, and composition
- Iterate and refine results step-by-step
- Use inpainting to edit specific areas
- Explore and invent custom styles
- Think like a visual storyteller













Seedance 2.0 has become one of the most closely watched AI video models in the world, not only because of what it can generate, but because of where it sits. Backed by ByteDance, the company behind TikTok, Douyin, CapCut, Doubao and Dreamina, Seedance is not just another model fighting for attention in a crowded AI video market. It is plugged into one of the most powerful creation and distribution ecosystems on the internet. That makes the obvious question harder to answer than it first appears: is Seedance 2.0 still the most used tool for generating AI videos? And if it is, how many daily users does it really have?
The honest answer is that Seedance 2.0 is very likely one of the most influential AI video systems currently available, and possibly the best-positioned model in the market by distribution. But there is no verified public figure for its standalone daily active users. ByteDance has disclosed major usage numbers for related products such as Doubao and CapCut, and outside firms have tracked the scale of those apps, but those numbers cannot be treated as Seedance-only usage. The model’s reach is enormous. Its exact daily creator base remains undisclosed.
The model is real, but the usage number is not
ByteDance officially introduced Seedance 2.0 as a multimodal audio-video generation model designed to produce short, polished, high-quality clips from text, images, audio and video references. Unlike earlier prompt-to-video tools that mostly generated isolated clips with limited control, Seedance 2.0 is built around richer input. Users can guide the model with multiple images, video clips and audio cues, allowing more control over style, scene structure, camera motion and sound.
That distinction matters. AI video is moving away from the novelty phase, where a user typed a surreal prompt and waited to see what happened. The new frontier is controllability. Creators, advertisers and studios want tools that can follow direction, maintain visual consistency and produce assets that fit real workflows. Seedance 2.0’s pitch is that it can help generate cinematic clips with synchronized audio, multiple shots and more coherent motion than many earlier systems.
This is why the model has generated so much attention. It is not merely a consumer toy. It has obvious applications in advertising, e-commerce, film previsualization, short-form entertainment, music videos, gaming concepts and social media production. A performance marketer can test dozens of video variations. A creator can build a fictional scene without a camera crew. A brand can produce short product videos at far lower cost. A filmmaker can experiment with visual ideas before committing to production.
But none of that proves that Seedance 2.0 is the most used AI video tool. Usage is not the same as technical quality. Nor is viral attention the same as daily active users. ByteDance has not released a public Seedance 2.0 daily active user count. There is no official number saying that a certain number of people use Seedance every day. Any precise figure should therefore be treated with caution unless it comes from ByteDance or a credible third-party measurement firm with clear methodology.
Why people think Seedance 2.0 is the leader
The belief that Seedance 2.0 may be the leading AI video tool comes from three overlapping signals: model quality, viral visibility and ByteDance’s distribution power.
On model quality, Seedance 2.0 has performed strongly in public comparisons and human-preference leaderboards. DeepLearning.AI has reported that Seedance ranked near the top in several video generation categories, including text-to-video and image-to-video tasks. Artificial Analysis has also placed Seedance among the leading systems, although not always as the outright winner in every category. In some rankings, Alibaba’s HappyHorse has challenged or beaten Seedance in specific areas, which shows that the competitive picture is not one-dimensional.
The fair conclusion is that Seedance 2.0 is a frontrunner, not an uncontested champion. It belongs in the top tier of AI video systems, especially where synchronized audio, cinematic composition and image-to-video generation matter. But AI video quality is changing quickly. The best model in one category this month may be second or third in another category next month.
The second signal is virality. Seedance 2.0 became a breakout topic almost immediately after launch, especially in China. Reuters described it as one of the most viral Chinese AI releases of the period, drawing comparisons to the excitement around DeepSeek. Clips generated with Seedance spread quickly across social platforms, including cinematic action scenes, anime-inspired videos, celebrity-style clips and fictional trailers.
The third and most important signal is distribution. Seedance 2.0 is not sitting inside a small standalone app hoping users discover it. It is connected to ByteDance’s broader ecosystem, including Dreamina, Doubao, CapCut and API channels. That gives it a structural advantage over many rivals. A company like Runway may have strong brand recognition among creative professionals. OpenAI’s Sora had enormous symbolic value. Kling, Hailuo, PixVerse and Vidu have strong user communities. But ByteDance owns some of the most important surfaces where short-form video is created, edited and distributed.
That is the real reason Seedance 2.0 matters. It is not only a model. It is a model attached to a machine.
The daily user question
The question “How many daily users does Seedance 2.0 have?” sounds simple, but it is not. Seedance is a model, not just an app. It can be used through multiple products and services. A user may access it through Dreamina. Another may encounter it through Doubao. A creator may use it inside CapCut. A business may use it through an API. A third-party platform may offer access to Seedance without making the model name visible to the end user.
That makes daily active user measurement difficult. If someone uses a CapCut AI video feature powered by Seedance, should they count as a Seedance user? If a marketer uses an API to generate 500 ad variants in a day, is that one user or 500 generated videos? If a creator edits a Seedance-generated clip but never directly prompts the model, should that count? Traditional app metrics do not map cleanly onto foundation model usage.
The best available public data relates to ByteDance products around Seedance, not to Seedance itself. Doubao, ByteDance’s AI assistant, has been reported by Reuters to have reached more than 100 million daily active users during a major holiday spike in China. QuestMobile data cited by Reuters also indicated that Doubao had more than 150 million weekly active users during a measured period. These are extremely large numbers and show that ByteDance has one of the biggest AI consumer funnels in the world.
CapCut is even more important internationally. Andreessen Horowitz, citing Sensor Tower data, placed CapCut among the largest consumer AI-related apps globally, with hundreds of millions of monthly active mobile users. CapCut’s importance comes from the fact that its users already arrive with creative intent. They are not casually asking a chatbot a question. They are making videos, editing clips, adding captions, applying templates and preparing content for platforms such as TikTok, Instagram Reels and YouTube Shorts.
However, none of those numbers equals Seedance 2.0 daily usage. Doubao’s daily users are not all generating videos. CapCut’s monthly users are not all using Seedance. Dreamina users are not all active every day. API customers may generate large volumes with relatively few human users. Therefore, the only responsible answer is that Seedance 2.0’s standalone DAU has not been publicly disclosed.
A cautious estimate would say that Seedance 2.0 has access to a potential user funnel in the hundreds of millions across ByteDance’s ecosystem, but the number of people actively generating Seedance videos each day is likely far smaller. It could be in the hundreds of thousands, millions or more during major spikes, but no public evidence supports a precise figure. The honest number is unknown.
Why “most used” may be the wrong metric
In consumer software, daily active users are a useful measure. In AI video, they can be misleading. A tool with millions of casual users producing one clip each may have less commercial importance than a tool used by agencies, creators and brands to generate thousands of campaign assets every day. A model’s impact depends on the volume of generated content, the quality of that content, the number of viewers it reaches and how deeply it becomes embedded in production workflows.
Seedance 2.0 may lead in some of those areas while remaining unproven in others. It likely has one of the largest potential creator funnels because of ByteDance. It appears to have strong technical performance. It has generated viral content. It is being positioned for professional and commercial use. But whether it is the single most used AI video tool by daily active creators cannot be verified.
This matters because the AI industry often confuses visibility with adoption. A model can dominate headlines while another dominates workflows. A product can go viral for a week while another quietly becomes the default tool for agencies. A leaderboard winner can lose the distribution battle. A technically weaker model can win if it is cheaper, faster and easier to access.
Seedance 2.0’s greatest strength is that it does not need to win only on benchmark quality. ByteDance can put it where creators already work. That is a far more durable advantage than a launch-week viral cycle.
How many people see Seedance-generated videos?
There is also no verified aggregate number for how many people watch Seedance-generated videos. But the viewing audience is almost certainly much larger than the creator base.
AI video has a strong multiplier effect. One person generates a clip. That clip is posted on TikTok, Douyin, X, Instagram Reels, YouTube Shorts, Weibo or Reddit. It is then reposted, stitched, remixed, criticized, embedded in articles and discussed by influencers. A single generated video can be seen by millions of people even if only one person created it.
Entertainment Weekly reported that one viral Seedance 2.0 clip featuring AI-generated versions of Tom Cruise and Brad Pitt fighting crossed more than 1 million views, while a follow-up with dialogue passed several million. Those examples do not prove total Seedance viewership, but they show the scale of distribution that generated clips can reach once they leave the original tool.
In China, Seedance-generated content is likely seen mainly on Douyin, Weibo, Dreamina-related communities and creator accounts using ByteDance tools. Douyin is especially important because it is not just a platform for watching short videos. It is part of a mature commercial ecosystem involving livestreaming, e-commerce, advertising, influencers and entertainment. If Seedance becomes a common input into Douyin-native content, its viewership could become massive without ever being reported as “Seedance views.”
Outside China, Seedance clips circulate across TikTok, X, Instagram Reels, YouTube Shorts, Reddit and technology media coverage. Some videos are clearly labeled as Seedance outputs. Many are not. Once a generated clip is edited, captioned, remixed and reposted, viewers may have no idea which model created it. That makes aggregate viewership almost impossible to measure from the outside.
The best answer is that Seedance-generated videos have already reached millions of viewers through individual viral clips, and potentially many more through distributed social sharing. But there is no public total view count for all Seedance-generated content.
Where Seedance videos are being watched
Seedance videos are not watched in one place. They move through a fragmented attention network.
In China, the most important viewing surfaces are likely Douyin and Weibo. Douyin gives Seedance access to one of the world’s most sophisticated short-video ecosystems. Weibo provides viral amplification, especially when AI clips involve celebrities, entertainment franchises or controversial uses of likeness and copyright. Doubao and Dreamina may also serve as creation and sharing surfaces, although their role is more closely tied to AI interaction and generation than pure video distribution.
Internationally, TikTok is the most obvious surface because of ByteDance’s global video footprint. However, Seedance videos also spread on X, where AI creators often post experiments and technical comparisons. Instagram Reels and YouTube Shorts are natural destinations because generated clips fit their format. Reddit communities focused on artificial intelligence, filmmaking, video tools and visual effects also help distribute examples.
Professional uses are less visible but potentially more valuable. Seedance-generated video can appear in product ads, pitch decks, previsualization reels, e-commerce listings, game concept presentations and social campaigns. These may not go viral as “AI videos,” but they can influence real marketing and creative production. In that sense, the most important Seedance outputs may eventually be the ones viewers do not recognize as Seedance outputs at all.
The CapCut factor
CapCut may be the decisive piece of the Seedance story.
Most AI video tools face a workflow problem. A user generates a clip in one product, downloads it, edits it somewhere else, adds captions in another tool, resizes it for social media and then uploads it to a platform. Every extra step creates friction. CapCut collapses that workflow.
CapCut already sits at the center of short-form video editing for millions of creators. It is used for captions, templates, effects, sound design, transitions and platform-ready formatting. If Seedance 2.0 becomes deeply integrated into CapCut, the model stops being an external generator and becomes part of the normal editing process.
That could make Seedance usage grow in a way that is almost invisible. A creator may not think, “I am using Seedance 2.0.” They may simply use an AI generation button inside CapCut. A social media manager may generate background footage, product scenes or transitions without caring which model powers the feature. A small business owner may create a promotional video from a product image and a prompt. In all these cases, the model wins by becoming infrastructure.
This is the same pattern that made AI image tools widespread. The technology did not scale only through specialist apps. It scaled when it appeared inside design software, social media tools, advertising platforms and workplace products. Seedance 2.0 is positioned to follow the same path in video.
Why rivals should not be underestimated
Seedance 2.0 is powerful, but the AI video market remains intensely competitive.
Kling has built strong recognition, particularly among creators who want realistic motion and cinematic outputs. Hailuo has gained traction with accessible generation and fast-moving model updates. PixVerse has attracted users with stylized and social-friendly outputs. Vidu has pushed image-to-video and animation-style generation. Runway remains influential among creative professionals and has deep brand recognition in AI filmmaking. Google’s Veo is backed by one of the strongest AI research organizations in the world. Alibaba’s HappyHorse has performed strongly in some independent evaluations.
This means Seedance is not operating in a vacuum. Leadership in AI video may shift depending on whether users care most about realism, speed, price, audio, camera motion, character consistency, commercial licensing, API access or social distribution. No single model clearly dominates every use case.
Seedance’s advantage is ecosystem leverage. Its weakness may be access, moderation and legal risk. If users face queues, restrictions or uncertain international availability, they may use alternatives. If brands are nervous about copyright issues, they may prefer tools with clearer commercial licensing. If rival models become cheaper or easier to integrate, agencies may diversify.
The market is too young for a permanent winner.
The copyright and likeness problem
Seedance 2.0’s viral success also exposed one of AI video’s biggest risks: unauthorized use of copyrighted characters and celebrity likenesses.
Reports from major media outlets described Seedance-generated clips involving recognizable entertainment properties, celebrities and fictional characters. Some of these clips drew fascination because of their quality. Others raised concerns about copyright infringement, impersonation and the ability to generate realistic scenes involving public figures. Business Insider reported that ByteDance said it would strengthen safeguards after complaints from rights holders, including Disney.
This issue directly affects usage. Open-ended generation creates virality because users can produce shocking, familiar or culturally loaded content. But the same openness creates legal exposure. Stronger guardrails may reduce misuse, but they may also reduce the viral appeal that helped the model spread in the first place.
For professional adoption, safeguards are necessary. Brands do not want to build campaigns on legally questionable assets. Agencies need confidence that generated content can be used commercially. Platforms need moderation systems that can prevent impersonation, deepfake abuse and copyright violations. Seedance 2.0’s long-term success will depend not only on model quality but on whether ByteDance can make it safe enough for serious commercial use without making it too restricted for creators.
The compute bottleneck
There is another constraint that matters: video generation is expensive.
High-quality AI video requires far more compute than text generation or even image generation. Every second of video involves many frames, temporal consistency, motion modeling and often audio synchronization. This makes scaling difficult. WIRED reported that early Seedance access involved queues and long waiting times, suggesting demand exceeded available compute capacity during the launch period.
That is not unusual. Many AI video products have faced the same issue. OpenAI’s Sora became famous before it became widely available, partly because serving high-quality video generation at scale is expensive and operationally difficult. Even when models work well in demos, turning them into mass-market products requires cost control, infrastructure and moderation.
This is another reason daily active users may not tell the full story. A model may have enormous demand but limited supply. If generation is rationed through credits, queues or paid access, the daily user count reflects infrastructure limits as much as consumer interest. Seedance 2.0 may be more popular than its actual usage numbers would suggest, simply because not every interested user can generate freely.
What “most used” could mean in practice
There are several ways Seedance 2.0 could be considered the most used AI video tool, but each requires a different definition.
It could be the most used by potential reach if CapCut and Doubao integrations expose it to hundreds of millions of users. It could be the most used by generated video volume if API customers, creators and platforms produce massive numbers of clips. It could be the most viewed if Seedance-generated videos circulate heavily on Douyin, TikTok and other social platforms. It could be the most influential if agencies, advertisers and creators treat it as a default production tool.
But it is not confirmed to be the most used by standalone daily active users, because no public Seedance-only DAU figure exists.
This distinction is important for investors, creators and competitors. For investors, the question is whether ByteDance can turn model quality and distribution into revenue. For creators, the question is whether Seedance gives them better outputs faster than alternatives. For advertisers, the question is whether it reduces production cost while increasing creative variation. For competitors, the question is whether they can match ByteDance’s ecosystem advantage.
Seedance does not need to win every category to be strategically dominant. It only needs to become the easiest high-quality video generation layer inside tools people already use.
The realistic estimate
The most defensible estimate is layered rather than precise.
Seedance 2.0 itself has no verified public daily active user count. ByteDance’s surrounding ecosystem reaches a very large audience. Doubao has been reported above 100 million daily active users during a major spike in China. CapCut has been reported to have hundreds of millions of monthly active mobile users globally. Dreamina and API integrations add further reach. But the number of users who actively generate Seedance 2.0 videos each day is undisclosed.
A careful formulation would be: Seedance 2.0 is exposed to a potential audience of hundreds of millions through ByteDance products, but its actual daily active generator base is unknown. It is almost certainly much smaller than CapCut’s total user base and smaller than Doubao’s total daily user base, because only a subset of those users generate video.
For viewership, individual Seedance-generated clips have reached millions of views. Total viewership across Douyin, TikTok, X, Instagram Reels, YouTube Shorts, Weibo and other platforms is unknown. It may be very large, but there is no public aggregate count.
Final verdict
Seedance 2.0 is not publicly proven to be the most used AI video generation tool by daily active users. The data needed to make that claim has not been released. ByteDance has disclosed or been associated with massive usage figures for related products, but those figures should not be mistaken for Seedance-only usage.
What can be said with confidence is that Seedance 2.0 is one of the most important AI video systems in the market. It is technically strong, highly visible, commercially relevant and attached to a distribution network that most rivals cannot match. Its integration with CapCut may be more important than any leaderboard score, because it places AI video generation directly inside the workflow of millions of creators.
The model’s future leadership will depend on four things: how widely ByteDance integrates it, how cheaply it can be served, how well it handles copyright and likeness risks, and whether creators find it easier and better than alternatives such as Kling, Runway, Hailuo, PixVerse, Vidu, Veo and Alibaba’s models.
For now, the clearest answer is this: Seedance 2.0 may be the best-positioned AI video model in the world, but its daily user count is not public. Its potential reach is enormous. Its actual creator base is undisclosed. Its videos are already being watched across Douyin, TikTok, X, Instagram Reels, YouTube Shorts, Weibo and professional marketing channels. And in the AI video race, that may be more important than a single DAU number.

A beautiful website used to begin with a blank canvas, a mood board, a design system, and hours of patient refinement. Today, it can begin with a sentence. “Create a cinematic landing page for an AI finance assistant with glassmorphism, scroll-triggered animations, dark mode, and an elegant dashboard hero.” In seconds, an AI tool can sketch the structure, write the copy, generate React components, apply Tailwind classes, add motion effects, and sometimes even deploy the result. The question is no longer whether AI can help design web pages. It can. The sharper question is which AI design tool produces the right kind of beauty, the right kind of animation, and the right kind of production-ready output for the job.
AI Web Design Has Moved Beyond Templates
The first wave of website builders simplified publishing, but they did not eliminate the design problem. Squarespace, Wix, WordPress themes, and Webflow templates made it easier to launch a site, yet most users still had to choose layouts, tune spacing, adjust breakpoints, write sections, and make the whole thing feel less generic.
The new generation of AI web design tools attacks the blank page directly. Instead of asking the user to pick from a gallery, these systems interpret a creative brief. They infer brand tone, structure pages, generate layouts, suggest typography, compose visual hierarchy, and increasingly add interaction. That matters because modern web design is not just a static arrangement of blocks. A premium landing page now depends on motion: animated hero text, parallax depth, hover states, scroll reveals, sticky product demos, dynamic gradients, interactive cards, micro-transitions, and dashboard mockups that feel alive.
The market has split into several categories. Claude, ChatGPT, and Gemini are flexible creative coding partners. Vercel’s v0, Lovable, and Bolt are app-generation environments. Framer, Webflow, Wix Studio, and Squarespace-style builders focus on hosted websites and visual editing. Figma and Relume sit earlier in the design workflow, shaping structure, wireframes, prototypes, and design systems before production. The best tool depends less on raw intelligence than on where the user wants to end up: a visual concept, a polished marketing page, a coded prototype, a CMS-driven website, or a full app.
Claude Design: The Most Interesting Creative Coding Partner
“Claude Design” has become a shorthand for the distinctive visual style that often emerges from Claude-generated interfaces: warm neutrals, elegant typography, shadcn-style cards, tasteful gradients, generous spacing, and polished SaaS-like layouts. The phrase has also become a warning. When many people ask the same model for “beautiful modern web design,” the results can converge. The New Yorker recently described the rise of a recognizable AI design aesthetic associated with Claude, especially around repeated color palettes, serif-heavy layouts, ticker-like elements, and open-source UI libraries such as shadcn/ui and Radix UI.
That criticism is fair, but it also reveals why Claude is so powerful. Claude is not only good at producing attractive surface design; it is good at explaining design choices, revising them in language, and generating runnable interface code. Anthropic’s Artifacts feature gives Claude a separate workspace for code, documents, visualizations, diagrams, and website designs, allowing users to iterate side by side with the conversation rather than copy code into a separate editor.
Claude’s biggest strength is taste plus reasoning. It can understand a creative direction like “less startup dashboard, more editorial luxury,” then rewrite both the visual system and the page copy around that idea. It is especially good when the user has a point of view. Ask for “a beautiful AI website” and Claude may produce something competent but familiar. Ask for “a Swiss-modern landing page for an AI model monitoring platform, with restrained motion, monochrome charts, brutalist typography, and an animated risk map,” and Claude becomes much more interesting.
For animations, Claude works best as a generator of custom code. It can write React components using Framer Motion, CSS keyframes, SVG animation, canvas effects, or lightweight JavaScript interactions. Anthropic has also positioned Claude as a creative coding assistant that can build shaders, procedural animations, and reusable scripts for design workflows.
The trade-off is that Claude is not a full website platform by itself. It can generate a beautiful page, but hosting, content management, analytics, responsive QA, accessibility testing, and production deployment require additional tools. Claude is excellent for ideation, interface code, design critique, and bespoke animation patterns. It is weaker when the project demands a complete end-to-end website system with client handoff, CMS collections, page management, and nontechnical editing.
Its best use case is the high-concept prototype: a landing page, interactive hero, product demo, calculator, dashboard preview, or animated storytelling section. For teams that already have developers, Claude is a design accelerator. For solo creators, it is a remarkable sketchpad. But to escape the “Claude Design” sameness, users must push it with specific art direction, brand constraints, unusual references, and manual editing.
v0: The Strongest Bridge Between Prompt and Production UI
Vercel’s v0 is one of the most important tools in AI web design because it sits close to the modern frontend stack. It was introduced as a generative UI product that turns descriptions into web interfaces, and Vercel now describes v0 as an AI agent for creating real code, full-stack apps, live prototypes, production deployments, and pull requests.
Where Claude feels like a brilliant creative collaborator, v0 feels like a product team member who understands React, Next.js, component structure, and Vercel deployment. That distinction matters. Many AI tools can create something that looks good in a preview. Fewer can create something that feels aligned with how engineering teams actually ship. v0 is strongest when the design target is a modern SaaS interface, dashboard, marketplace, analytics product, developer tool, or AI app.
Its design output tends to be clean, polished, componentized, and immediately familiar to teams using React and Tailwind. Vercel’s own materials describe v0 as capable of producing structured, styled React components from text prompts and taking ideas from prototype toward deployed web experiences.
For animations, v0 is practical rather than cinematic by default. It can generate hover states, animated tabs, transitions, accordions, loading states, scroll effects, and interactive components. It can also use common animation libraries when prompted clearly. But its strongest animation use case is interface motion, not pure visual spectacle. When the goal is a smooth dashboard card expanding into a modal, a pricing toggle that feels refined, or a product tour with elegant transitions, v0 performs very well. When the goal is a wildly artistic WebGL homepage with particle systems and surreal motion, Claude or a specialist creative coding workflow may be better.
v0’s weakness is that its aesthetic can also become recognizable. Like Claude, it often leans into the modern component-library look: rounded cards, gradients, clean spacing, muted backgrounds, and polished but safe SaaS sections. The difference is that v0 is closer to production. It is less a visual dream machine and more a fast path from prompt to usable interface.
For startups building AI products, v0 is one of the best tools available. It is not merely designing a page; it is helping define the product surface. A founder can prompt a landing page, dashboard, onboarding flow, settings page, and pricing screen, then hand the output to engineers with far less translation. Among the tools in this comparison, v0 is the strongest choice when design and code handoff are equally important.
Framer AI: The Fastest Route to a Beautiful Marketing Site
Framer occupies a different position. It is not primarily an app builder, and it is not just a coding assistant. It is a design-forward website builder with strong publishing, animation, and visual editing. Framer says its AI tools can generate layouts and advanced components quickly, while its AI agent can create custom effects, interactions, live-data components, and code placed directly into a site.
Framer’s advantage is speed to beauty. When the assignment is a portfolio, product landing page, waitlist page, creator site, agency homepage, or launch microsite, Framer often feels more natural than v0 or Claude. The visual editor encourages refinement. Designers can adjust layout, typography, responsiveness, and motion without living entirely in code. Framer’s animation model is also one of its great strengths. It has long appealed to designers who want interactive, polished web pages without building everything manually in React.
AI makes Framer especially attractive for users who want to start with a strong layout but still expect to polish visually. A prompt can produce the initial site direction, but the tool’s real value appears in the second stage: tuning the composition, adding transitions, creating scroll effects, and making the page feel premium. Compared with Claude, Framer is less open-ended but more publishable. Compared with v0, it is less developer-native but more designer-friendly. Compared with Wix Studio, it is more stylish and startup-oriented, though less broad as an agency operations platform.
Framer’s limitation is depth. For content-heavy sites, complex CMS requirements, enterprise governance, or multi-role client management, it may not be the final answer. For full-stack apps, it is not trying to compete directly with Lovable or Bolt. But for animated marketing pages, it is one of the strongest options. The design output tends to feel contemporary, sleek, and launch-ready, especially when the user already has brand assets and a clear visual direction.
Framer is the tool to choose when the website itself is the product’s first impression. It is not the broadest AI builder. It may not generate the most complex backend. But when beauty, movement, and publishing speed matter most, Framer deserves a top-tier place.
Figma Make and Figma Motion: The Designer’s AI Workbench
Figma remains the central workspace for many product and brand teams, and its AI push is significant because it brings generative design into the place where design systems already live. Figma describes its AI design tools as a way to use natural language to create layouts, styles, and structures while retaining design control in the workspace.
The most important shift is that Figma is not only generating static frames. Figma has introduced native motion capabilities, including the ability to prompt an agent to create motion directly on an animation timeline. Figma’s own announcement says motion is now native to the canvas, with Dev Mode support designed to improve handoff.
This makes Figma uniquely powerful for teams that care about design quality before code. Claude, v0, and Bolt can generate interfaces quickly, but they often skip the disciplined design process. Figma keeps the work inside a collaborative environment where designers can inspect components, align to libraries, review motion, and prepare handoff. For large organizations, that matters more than raw generation speed.
Figma’s AI strength is not necessarily that it produces the most finished website from one prompt. Its strength is controllable ideation. A designer can explore layout directions, generate visual assets, test hierarchy, create variants, and now experiment with motion without leaving the design canvas. This makes it especially useful for brands that cannot accept generic AI output. When a company already has a design system, Figma’s AI can accelerate within that system rather than replacing it.
The weakness is that Figma is not inherently a web publishing platform. A Figma prototype can look gorgeous and move beautifully, but it still needs translation into production code unless paired with tools or workflows that handle design-to-code. Recent research into Figma-to-code workflows underscores the difficulty: even advanced models can struggle with responsiveness and maintainable code when converting rich design files into production interfaces.
Figma is therefore best for design teams, not necessarily solo founders trying to launch by tonight. It is the strongest tool for shaping the visual language of a serious product. If Claude is the creative coder and v0 is the frontend accelerator, Figma is the design authority.
Webflow AI: The Best Fit for Serious Marketing Websites With CMS Needs
Webflow has always appealed to designers who want production-grade websites without surrendering visual control. Its AI direction builds on that identity. Webflow positions itself as an AI-native web platform for creating and optimizing web experiences, with hosting, CMS, analytics, enterprise features, and AI-assisted building in one environment.
Webflow’s AI Assistant can modify page designs, automate repetitive site-building tasks, and tailor new sections to match the context of an existing site, including styles and content. Its help documentation specifically mentions use cases such as navbars, footers, testimonials, hero sections, and other standard page elements.
This context-awareness is the key. Many AI tools are impressive on page one and weaker on page twenty. Webflow’s advantage is continuity. For a business website with a CMS, blog, resource library, landing pages, case studies, localization needs, SEO workflows, and brand governance, the challenge is not just generating a beautiful hero section. It is maintaining a coherent system across dozens or hundreds of pages.
For animations, Webflow is already strong. Its interaction engine enables scroll-based reveals, parallax effects, hover states, page-load sequences, and complex timeline-style animations. AI can accelerate section creation, copy adaptation, and layout adjustments, while Webflow’s native tools allow designers to polish motion manually. That combination makes Webflow a serious choice for agencies and in-house marketing teams.
The trade-off is complexity. Webflow has a learning curve, and its AI features are most valuable when the user understands the underlying design environment. It is less magical than a pure prompt-to-site builder, but more durable for serious web operations. Compared with Framer, Webflow is stronger for structured content and scalable marketing systems. Compared with Wix Studio, it offers a more designer-developer feel. Compared with Claude or v0, it gives up some open-ended coding flexibility in exchange for a mature website platform.
Webflow is the best choice for teams that want polished, animated marketing websites with real CMS architecture. It is less suited to someone who wants a complete app generated from a single prompt.
Wix Studio: The Agency-Friendly AI Platform
Wix Studio has become more than a simple website builder. It is aimed at agencies, freelancers, and professional teams managing multiple client sites. Wix Studio highlights creative freedom, responsive design, custom code, API integrations, GitHub integration, AI-powered workflow features, visual sitemaps, wireframe generation, collaboration, roles, permissions, and client management.
Its most interesting AI feature for design execution is Responsive AI. Wix says the tool identifies groups of related layout elements, applies appropriate layout structures such as grids or stacks, and adjusts sizing and responsive behavior so sections work across breakpoints.
That may sound less glamorous than “generate a stunning site from a sentence,” but responsive cleanup is one of the most painful parts of web design. A desktop layout that looks beautiful can fall apart on tablet or mobile. AI that can repair section responsiveness is valuable because it addresses a real production bottleneck rather than only the early creative phase.
Wix Studio’s strength is operational. Agencies need more than beautiful pages. They need client handoff, collaboration, permissions, content editing, templates, billing logic, and reliable hosting. TechRadar’s 2026 review described Wix Studio as an all-in-one platform for professional web designers and agencies, noting collaboration, role-based permissions, responsive design, Figma integration, CMS capabilities, and client handoff features.
For animations, Wix Studio can produce polished commercial websites, though it may not feel as fluidly design-native as Framer or as technically open as custom React. Its best animation use case is client-ready visual polish: transitions, reveals, interactive sections, and responsive effects that support a brand site rather than dominate it.
The downside is platform lock-in and aesthetic ceiling. Wix Studio is powerful, but advanced designers may still prefer the control of Webflow or Framer, while developers may prefer v0, Lovable, Bolt, or Claude-generated code. Wix Studio wins when the client workflow matters as much as the design itself.
Relume: The Best AI Tool for Structure Before Style
Relume is often misunderstood because it is not trying to be the flashiest AI website generator. Its core strength is planning. Relume says it can generate sitemaps, wireframes, and style guides for marketing websites in minutes, positioning AI as a design ally rather than a replacement.
That makes Relume extremely useful in professional workflows. Many bad websites are not bad because the gradient is wrong. They are bad because the structure is wrong. The homepage does not explain the product. The navigation is confusing. The feature sections are repetitive. The conversion path is weak. Relume starts with information architecture, which is often where AI can create the most leverage.
The workflow is especially strong for agencies building marketing sites. A designer can generate a sitemap, turn it into wireframes, develop copy direction, then export or continue into tools like Figma and Webflow. Relume’s documentation emphasizes building sitemaps with AI and iterating from prompts and page structures.
For animations, Relume is not the primary tool. It does not compete with Framer’s interactive polish or Claude’s creative coding. Its contribution is earlier: it gives motion a reason to exist. When a page has the right sections in the right order, animation can reinforce the story. Without structure, motion becomes decoration.
Relume’s limitation is that it does not produce the final “wow” alone. It is a strategist’s tool, a wireframing accelerator, and a content-architecture assistant. It pairs beautifully with Webflow, Figma, Framer, Claude, or v0. For serious teams, that is not a weakness. It means Relume belongs near the start of the process, before visual style and animation are overlaid.
Relume is the strongest choice when the brief is still messy. When a founder says, “We need a new site for our AI compliance product, but we do not know the pages or sections,” Relume can bring order before the visual tools take over.
Lovable: The Founder’s Fast Track From Idea to Product
Lovable belongs to the “AI app builder” category. It is not only about making a page beautiful; it is about turning a product idea into a working web app or MVP. Lovable describes itself as a platform for building apps, websites, and digital products faster using AI, without requiring deep coding skills.
Its strength is breadth. A founder can generate landing pages, authentication flows, dashboards, database-connected features, and product logic through conversation. Lovable’s materials for designers emphasize visual control, React and Tailwind output, workspace themes for consistency, and GitHub sync for developer handoff.
This makes Lovable compelling for AI startups, crypto tools, marketplaces, internal platforms, and early SaaS products. A beautiful landing page is useful, but a landing page connected to a working demo is more powerful. Lovable is strongest when the site is attached to actual product behavior.
For animations, Lovable can generate modern UI motion, especially when prompted with specific libraries or interaction patterns. Its aesthetic tends toward modern web app design rather than pure brand storytelling. It can create attractive dashboards, onboarding screens, forms, cards, and marketing sections, but its biggest advantage is functional continuity. The user can ask for a beautiful pricing page, then a signup flow, then a database table, then an admin dashboard.
The trade-off is that Lovable may require more refinement for high-end brand expression. It is a product builder first and a visual design studio second. A designer can push it toward more distinctive results, but without strong direction it may produce polished, conventional startup UI. That is still valuable. Most early-stage products need clarity, coherence, and speed more than award-winning art direction.
Lovable is best for founders who need a working product surface fast. It is less ideal for agencies crafting a highly bespoke brand site where every animation and visual detail must be art-directed.
Bolt: The Browser-Based Builder for Working Apps and Fast Experiments
Bolt is another major AI builder, and its positioning is direct: type an idea into chat, build websites, web apps, and mobile apps, and move from prompt to working product. Bolt’s support documentation describes it as an AI-powered builder for websites, web apps, and mobile apps that transforms a typed idea into a working product.
Bolt’s defining characteristic is its development environment. It is connected to StackBlitz’s WebContainers, meaning it can run a development environment in the browser. Bolt’s own troubleshooting materials note that it relies on WebContainers, a browser-based runtime from StackBlitz, to enable full-stack development in the browser.
That gives Bolt a “build while you watch” feeling. It can generate files, run the app, show errors, revise code, and iterate in one place. For web pages with animations, this is useful because animation bugs are often visual and runtime-dependent. Seeing the result immediately matters.
Bolt is strong for rapid demos, hackathon-style builds, internal tools, landing pages with interactive elements, and early full-stack concepts. It may not always produce the most refined visual design on the first try, but it is effective when the user wants a working app and is willing to iterate. Compared with Lovable, Bolt feels more like a live coding environment. Compared with v0, it is broader in browser-based app construction. Compared with Claude, it is more operational and less conversationally nuanced.
Its weakness is that browser-based generation can still hit technical friction. Dependencies, runtime errors, and generated architecture choices require supervision. The user gets speed, but not a guarantee of perfect engineering. For serious production work, developers should review the code, dependencies, security model, and maintainability.
Bolt is best when the priority is momentum. It shines for builders who want to move from idea to running interface quickly, especially when the final result includes more than a static marketing page.
The Animation Question: Who Makes Motion Feel Premium?
Animation separates a merely attractive AI-generated website from a memorable one. But “cool animations” can mean several things.
For micro-interactions, v0, Claude, Framer, Webflow, Lovable, and Bolt can all perform well. These include hover effects, animated buttons, accordions, tabs, cards, loading states, and modal transitions. v0 is particularly strong when the animation belongs to a React component. Claude is excellent when the animation needs custom logic or creative coding. Framer is excellent when the designer wants to tune the feel visually.
For scroll-based storytelling, Framer and Webflow are the strongest mainstream choices. Their visual interaction models make it easier to polish timing, easing, section reveals, sticky layers, and page transitions. Claude can code these effects, but the workflow is less visual. v0 can generate them, but the final art direction often requires manual refinement.
For motion design inside the design process, Figma Motion is becoming more important. Prompting motion directly on a timeline changes the early creative phase because teams can explore animation before writing code. That is especially valuable for product teams that need stakeholder approval before engineering begins.
For experimental animation, Claude is the most flexible. It can generate SVG morphing, canvas particles, shader-like effects, procedural backgrounds, WebGL experiments, and data-driven animations when the user gives enough detail. The risk is maintainability. A spectacular AI-generated animation can become difficult to debug or optimize when it was produced without constraints.
For practical animated product pages, Framer is the best balance of speed and polish. For production UI components, v0 is the best. For full creative freedom, Claude wins. For structured marketing systems, Webflow wins. For working MVPs with interactive screens, Lovable and Bolt are strongest.
Beauty Versus Brand: The Hidden Weakness of AI Design
The biggest weakness across all tools is not technical. It is sameness. AI design systems are trained on the existing web, and the existing web already has dominant patterns: rounded cards, soft gradients, glowing orbs, oversized hero copy, dashboard mockups, pill buttons, floating logos, bento grids, and dark-mode SaaS pages.
This is why Claude Design became recognizable. It is also why v0 pages, Lovable MVPs, and Framer AI drafts can sometimes feel like siblings. The tools are not failing; they are optimizing toward what users repeatedly ask for. When users prompt “modern, clean, beautiful,” models converge on the median of modern beauty.
The solution is not to reject AI. The solution is to become a better creative director. Strong prompts should include audience, brand personality, emotional target, forbidden clichés, typography direction, motion restraint, layout references in words, accessibility expectations, and technical constraints. A good prompt does not say “make it pop.” It says, “Use a restrained editorial layout, avoid neon gradients, animate only the data visualization and section transitions, keep typography compact and institutional, and make the hero feel like a Bloomberg terminal redesigned by a luxury magazine.”
AI can generate beauty, but distinctive beauty still requires taste. The designer’s role shifts from arranging every pixel to defining the aesthetic rules, rejecting generic output, and knowing when motion supports the story rather than distracting from it.
Which Tool Is Best?
Claude is the best creative coding partner. It is ideal for bespoke animated sections, experimental interfaces, rapid visual exploration, and intelligent design iteration. Its weakness is that it needs external deployment and careful art direction to avoid generic Claude Design.
v0 is the best prompt-to-production UI tool for React and Next.js teams. It shines when polished interface code, component structure, and engineering handoff matter. Its weakness is that its default aesthetic can feel familiar unless customized.
Framer is the best tool for beautiful animated marketing sites launched quickly. It gives designers the easiest path from prompt to polished web presence. Its weakness is that it is not a full-stack product builder.
Figma is the best AI-enhanced design workspace. It is where serious teams should shape systems, prototypes, and motion before production. Its weakness is that it still needs a translation path into code or a publishing platform.
Webflow is the best AI-assisted platform for scalable marketing websites with CMS needs. It combines design control, hosting, CMS, and interactions. Its weakness is complexity and a steeper learning curve.
Wix Studio is the best agency-friendly AI website platform. Its responsive AI and client-management features solve practical production problems. Its weakness is that advanced designers and developers may want more control or portability.
Relume is the best structure-first planning tool. It is excellent for sitemaps, wireframes, and marketing-site architecture. Its weakness is that it is not the final animation or visual polish layer.
Lovable is the best founder-focused full-stack AI builder when the website and product need to emerge together. Its weakness is that high-end brand expression may need additional design refinement.
Bolt is the best browser-based rapid build environment for turning ideas into running apps quickly. Its weakness is that generated apps still require technical review before serious production use.
The Smartest Workflow Is Not One Tool
The most capable teams will not choose a single winner. They will combine tools.
A strong AI web design workflow might start in Relume to generate the sitemap and wireframe logic. It might move to Figma to define visual language, components, and motion concepts. Claude could then generate an experimental animated hero or custom visualization. v0 could translate key interface patterns into React components. Framer could publish a campaign landing page, while Webflow could manage the main marketing site and CMS. Lovable or Bolt could build the functional MVP that sits behind the “Get started” button.
This layered workflow mirrors how serious websites are already made. Strategy, structure, design, motion, code, content, publishing, and optimization are different jobs. AI compresses the distance between them, but it does not erase the need to know which layer you are working on.
Final Verdict: AI Can Design Beautiful Animated Websites, but Taste Still Wins
AI can now generate web pages that would have looked impressive even a few years ago: polished typography, responsive layouts, animated components, interactive dashboards, cinematic hero sections, and production-like prototypes. The strongest tools are no longer toys. Claude, v0, Framer, Figma, Webflow, Wix Studio, Relume, Lovable, and Bolt each solve a different part of the modern design-to-build pipeline.
Claude is the most imaginative. v0 is the most developer-aligned. Framer is the most instantly beautiful for animated marketing pages. Figma is the most serious design environment. Webflow is the strongest scalable website platform. Wix Studio is the most practical for agencies. Relume is the best strategic planner. Lovable and Bolt are the fastest routes from concept to working product.
The future of AI web design will not belong to the tool that produces the flashiest first draft. It will belong to workflows that combine speed with judgment. AI can generate the layout, code the animation, and suggest the copy. But the difference between a pretty page and a memorable digital experience still comes from direction: knowing what to remove, what to emphasize, when to move, when to stay still, and how to make a brand feel like itself rather than like the internet’s average idea of beauty.
AI Model
Anthropic’s Mythos and the New Cybersecurity Reality: When AI Finds the Cracks in America’s Most Sensitive Systems

The race to build more powerful artificial intelligence systems has largely been framed around productivity, scientific discovery, and economic transformation. Yet a revelation involving Anthropic’s advanced AI model, Mythos, highlights a different and potentially more consequential dimension of the AI revolution: cybersecurity.
According to reports emerging from U.S. government circles, Anthropic’s Mythos model was able to identify vulnerabilities within classified government computer systems during a controlled testing initiative conducted alongside intelligence agencies. The disclosure has reignited debate about the speed at which AI-powered cyber capabilities are advancing and what happens when machines become exceptionally good at finding weaknesses in critical infrastructure.
The development is significant not because an AI system hacked government networks in the Hollywood sense of the word, but because it demonstrates how rapidly frontier AI models are evolving into highly capable security researchers. For governments, corporations, and cybersecurity professionals, the implications are difficult to ignore.
A Test That Turned Heads Across Washington
The reports center on a government-linked initiative known as Project Glasswing, a collaborative effort involving Anthropic, intelligence agencies, and technology partners. The project’s objective is straightforward but critically important: discover vulnerabilities before hostile actors can exploit them.
During testing, Mythos reportedly identified vulnerabilities within classified U.S. government systems in a matter of hours. Statements attributed to officials suggest the model demonstrated an ability to uncover weaknesses at a pace that surprised even experienced cybersecurity personnel.
The details remain classified, and officials have emphasized an important distinction. Identifying a vulnerability does not necessarily mean the AI successfully exploited it. Security experts often separate vulnerability discovery from active compromise, and government representatives have been careful to note that Mythos located weaknesses rather than autonomously conducting destructive attacks.
That nuance matters.
Yet even with that clarification, the story captured attention because vulnerability discovery is one of the most valuable and difficult activities in cybersecurity. Organizations spend billions of dollars annually searching for weaknesses before attackers can find them. If advanced AI can dramatically accelerate that process, the cybersecurity landscape could change faster than many expected.
The Evolution of AI From Assistant to Security Researcher
For years, AI systems have been used to help cybersecurity teams analyze logs, identify suspicious behavior, and automate repetitive tasks. Those capabilities improved efficiency but did not fundamentally alter the balance between attackers and defenders.
Mythos appears to represent something different.
Rather than simply assisting human analysts, the model is designed to reason about software systems, inspect code, identify flaws, and prioritize security risks. Earlier disclosures from Anthropic indicated that Mythos had already detected thousands of potential vulnerabilities across open-source software projects. The company reported findings numbering in the tens of thousands across more than a thousand projects, with many categorized as severe vulnerabilities.
This shift transforms AI from a passive cybersecurity tool into an active discovery engine.
Historically, vulnerability research required highly specialized expertise. Elite researchers spent years learning operating systems, programming languages, networking architectures, and exploitation techniques. Even then, uncovering previously unknown flaws could require weeks or months of investigation.
Frontier AI models are beginning to compress that timeline.
Instead of manually reviewing thousands of lines of code, researchers can now deploy AI systems capable of scanning vast software environments, testing hypotheses, and highlighting likely security issues in a fraction of the time. While human validation remains essential, the productivity gains are substantial.
The result is a new category of AI capability that sits at the intersection of software engineering, cyber offense, and cyber defense.
Why Classified Systems Matter
Government agencies routinely manage some of the most sensitive digital environments in existence.
These systems can contain intelligence information, military planning data, communications infrastructure, and operational technologies tied directly to national security. They are protected through layers of technical controls, compartmentalization, monitoring systems, and rigorous access restrictions.
When reports emerge that an AI model successfully identified vulnerabilities within such environments, the significance extends beyond the specific bugs involved.
The story becomes a measure of capability.
If an AI system can rapidly uncover weaknesses in highly secured government infrastructure, it raises questions about how effectively similar models could analyze corporate networks, financial systems, cloud environments, telecommunications platforms, and critical infrastructure.
The concern is not limited to what today’s models can do. It is also about the trajectory.
Cybersecurity professionals have long understood that vulnerability discovery scales with intelligence. Better researchers find more bugs. More capable AI systems could therefore become increasingly effective at discovering weaknesses as their reasoning abilities improve.
The classified-system tests offer a glimpse into where that trajectory may lead.
Project Glasswing and the Defensive AI Strategy
The government’s involvement in Project Glasswing reveals an emerging strategic approach to AI security.
Rather than waiting for adversaries to weaponize advanced models, agencies appear increasingly interested in deploying frontier AI systems to strengthen defenses proactively.
This mirrors historical patterns in cybersecurity.
Many technologies initially associated with offensive capabilities eventually become defensive necessities. Encryption, penetration testing, vulnerability scanning, and threat intelligence all followed similar paths.
Organizations once debated whether automated scanning tools were dangerous because attackers could use them. Today, nearly every security team relies on such tools.
The same logic may apply to AI-powered vulnerability discovery.
If advanced models can locate security flaws more effectively than humans alone, governments may conclude they have little choice but to integrate these systems into security operations. Refusing to do so could leave defenders operating at a disadvantage while adversaries adopt increasingly capable AI tools.
Project Glasswing appears to represent an early version of that strategy: using AI to identify weaknesses before hostile actors do.
The Growing Tension Between Capability and Control
The Mythos story emerges against a backdrop of growing concern over frontier AI governance.
Recent reports suggest that tensions have developed between Anthropic and U.S. policymakers over the deployment and accessibility of some advanced models. Discussions around export controls, national security reviews, and access restrictions have intensified as AI capabilities continue to improve.
At the heart of the debate is a difficult question.
How should governments manage technologies that can be extraordinarily beneficial while simultaneously creating new categories of risk?
A model capable of finding critical vulnerabilities can help secure software. The same capability could potentially assist malicious actors seeking to discover weaknesses before defenders can patch them.
This dual-use nature is not unique to AI.
Cryptography, nuclear technology, biotechnology, and advanced computing have all faced similar challenges. Powerful tools often create both opportunity and risk.
The challenge with AI is speed.
Technological advances that once unfolded over decades now occur over months. Policymakers accustomed to traditional regulatory timelines are struggling to keep pace with systems whose capabilities improve dramatically from one model generation to the next.
The Cybersecurity Arms Race Is Accelerating
The Mythos revelation arrived shortly after warnings from intelligence officials across the Five Eyes alliance regarding the future of AI-driven cyber threats.
Security agencies from the United States, United Kingdom, Canada, Australia, and New Zealand have warned that advanced AI systems could significantly increase the sophistication and scale of cyberattacks in the near future. According to those assessments, the window separating vulnerability discovery and exploitation may continue shrinking as AI capabilities improve.
That trend creates challenges for both public and private organizations.
Traditionally, defenders enjoyed some breathing room after a vulnerability was discovered. Security teams could assess the issue, develop patches, and coordinate responses.
AI threatens to compress every stage of that cycle.
Vulnerabilities may be discovered faster.
Exploitation techniques may be generated faster.
Attack campaigns may be launched faster.
Defensive responses will need to accelerate accordingly.
This dynamic resembles an arms race in which both attackers and defenders gain access to increasingly capable automation.
The winner may not be the side with the most sophisticated AI, but the side capable of integrating AI most effectively into operational workflows.
What Mythos Reveals About Software Security
Perhaps the most uncomfortable lesson from the story is not about AI at all.
It is about software.
Modern digital infrastructure remains astonishingly complex. Governments, corporations, and critical infrastructure operators depend on millions of lines of code written over decades by countless developers. Vulnerabilities are inevitable.
The fact that an advanced AI system can uncover weaknesses rapidly does not necessarily indicate a failure of security teams. Instead, it reflects the reality that software ecosystems contain enormous numbers of potential attack surfaces.
Many organizations continue operating legacy systems, maintaining aging codebases, and relying on third-party software components that may harbor hidden flaws.
AI simply shines a brighter light on those weaknesses.
In that sense, Mythos may be exposing an existing problem rather than creating a new one.
The vulnerabilities were already there.
The AI merely found them more efficiently.
The Future of AI-Powered Vulnerability Hunting
The cybersecurity industry is already adapting to this new reality.
Companies increasingly view AI not as a productivity enhancement but as a force multiplier capable of transforming entire security workflows.
Future vulnerability research may look dramatically different from today’s methods.
Human experts could supervise fleets of specialized AI agents performing code analysis, fuzz testing, configuration review, exploit simulation, and remediation planning simultaneously.
Security assessments that once required months could potentially be completed in days.
Large enterprises might continuously scan their infrastructure with AI systems operating around the clock.
Government agencies could deploy advanced models to monitor critical systems in real time.
The implications extend beyond vulnerability discovery.
AI may eventually assist with patch development, incident response, threat hunting, malware analysis, and strategic cyber defense planning.
The Mythos tests offer a preview of what that future could look like.
Why the Human Element Still Matters
Despite impressive progress, AI is not replacing cybersecurity professionals anytime soon.
The reports surrounding Mythos highlight the importance of human oversight. Finding a potential vulnerability is only the beginning of the process. Researchers must verify findings, assess severity, determine exploitability, coordinate disclosure, and implement fixes.
False positives remain a challenge.
Context matters.
Operational decisions require judgment.
Even highly capable AI systems operate within constraints defined by humans.
The most effective cybersecurity organizations of the future are likely to combine human expertise with AI-driven automation rather than relying exclusively on either approach.
Experienced analysts provide strategic thinking, contextual understanding, and risk assessment capabilities that current AI systems still struggle to replicate consistently.
AI expands human reach.
It does not eliminate the need for human decision-making.
National Security in the Age of Frontier Models
The Mythos episode ultimately represents more than a cybersecurity story.
It is a national security story.
Governments increasingly recognize that advanced AI capabilities may become strategic assets comparable to cryptography, satellite technology, or advanced semiconductors.
The ability to discover vulnerabilities rapidly could influence intelligence operations, military planning, critical infrastructure protection, and cyber deterrence strategies.
As a result, AI development is becoming intertwined with geopolitical competition.
Countries that successfully harness frontier AI for defensive security applications may gain significant advantages in protecting critical infrastructure and reducing cyber risk.
Conversely, nations that fall behind could find themselves increasingly exposed.
The challenge is ensuring that defensive adoption outpaces offensive misuse.
That balance may define the next decade of cybersecurity policy.
A Glimpse Into the Next Phase of AI
The reports surrounding Anthropic’s Mythos model reveal a simple but profound reality: AI is no longer merely generating text, writing code, or answering questions.
It is beginning to function as a sophisticated security researcher.
The discovery of vulnerabilities within classified U.S. government systems during controlled testing demonstrates the extraordinary potential of frontier AI models to transform cybersecurity. While officials have emphasized that Mythos identified weaknesses rather than autonomously exploiting them, the speed and scale of its findings underscore how rapidly these systems are advancing.
For defenders, that capability offers enormous promise. AI could help identify weaknesses before adversaries find them, strengthen critical infrastructure, and accelerate security operations across entire industries.
For policymakers, it raises difficult questions about governance, access controls, and national security.
For organizations everywhere, it delivers a clear message: the cybersecurity landscape is entering a new era, one in which artificial intelligence becomes a central participant in the ongoing struggle between those who secure systems and those who seek to compromise them.
The vulnerabilities uncovered by Mythos may eventually be patched and forgotten. The broader lesson, however, is likely to endure. The age of AI-powered cybersecurity has arrived, and its impact will be felt far beyond the walls of classified government networks.
-

 AI Model11 months ago
AI Model11 months agoTutorial: How to Enable and Use ChatGPT’s New Agent Functionality and Create Reusable Prompts
-

 AI Model10 months ago
AI Model10 months agoTutorial: Mastering Painting Images with Grok Imagine
-

 AI Model9 months ago
AI Model9 months agoHow to Use Sora 2: The Complete Guide to Text‑to‑Video Magic
-

 AI Model12 months ago
AI Model12 months agoMastering Visual Storytelling with DALL·E 3: A Professional Guide to Advanced Image Generation
-

 Tutorial9 months ago
Tutorial9 months agoFrom Assistant to Agent: How to Use ChatGPT Agent Mode, Step by Step
-

 News11 months ago
News11 months agoAnthropic Tightens Claude Code Usage Limits Without Warning
-

 AI Model1 year ago
AI Model1 year agoCrafting Effective Prompts: Unlocking Grok’s Full Potential
-

 News9 months ago
News9 months agoOpenAI’s Bold Bet: A TikTok‑Style App with Sora 2 at Its Core